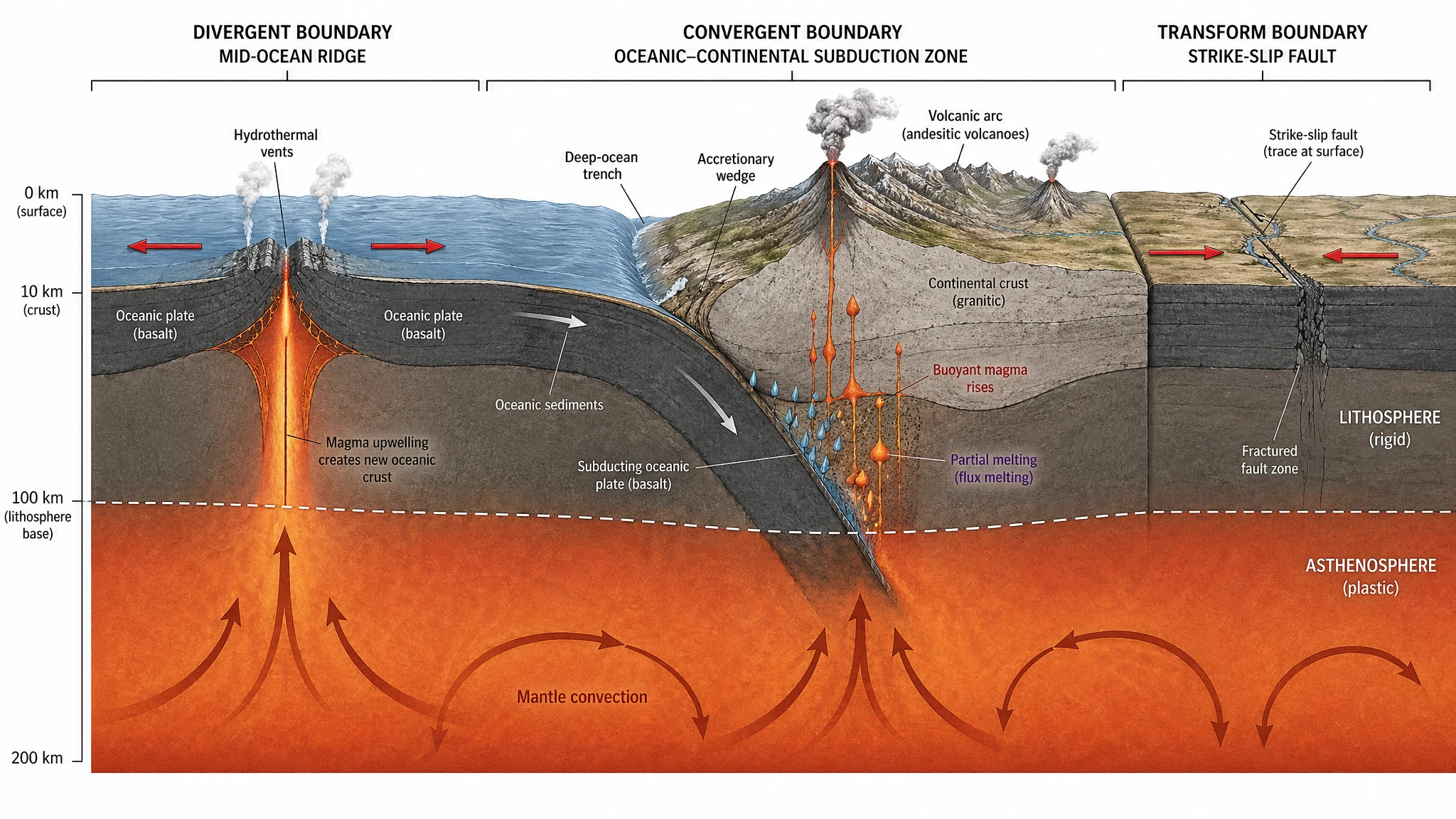
"哪款更强"是个伪问题
进入发现之前,先看两款旗舰各自"为什么场景而生"的速查表:
| 维度 | GPT Image 2 | Nano Banana Pro |
|---|---|---|
| 母公司 | OpenAI | Google(Gemini 3) |
| 为什么场景生 | 细节密集、规格严格的图 | 编辑级、构图优先的图 |
| 强项 | 化学规范、数学公式、抽象拓扑、长 prompt 命中 | 可读性、审美精致度、结构图(CS / 流程 / 机制) |
| 弱项 | 信息密度有时变拥挤 | 长 prompt 命中率低 13 个百分点;偶尔会概念渲染错误 |
| 默认场景 | 期刊投稿 | 幻灯片 / 海报 / 网页 |
| SciFig 入口 | /models/gpt-image-2 | /models/nano-banana-pro |
三个决定性发现(大概率适用于你)
我们从 24 张图的盲测里提炼了三个发现,应该改变你"默认开哪款"的习惯。决定性是说:分差大到掷硬币选会出错。
发现 1:化学论文必选 GPT Image 2(差距非常大)
‡ 符号、给反应物和产物都标了 R 和 S 立体配置、把五配位碳和三个三角面氢正确呈现、附带了完整能量图(含 Ea 活化能标注)、还自带四色图例(亲核试剂 / 离去基团 / 碳 / 氢)。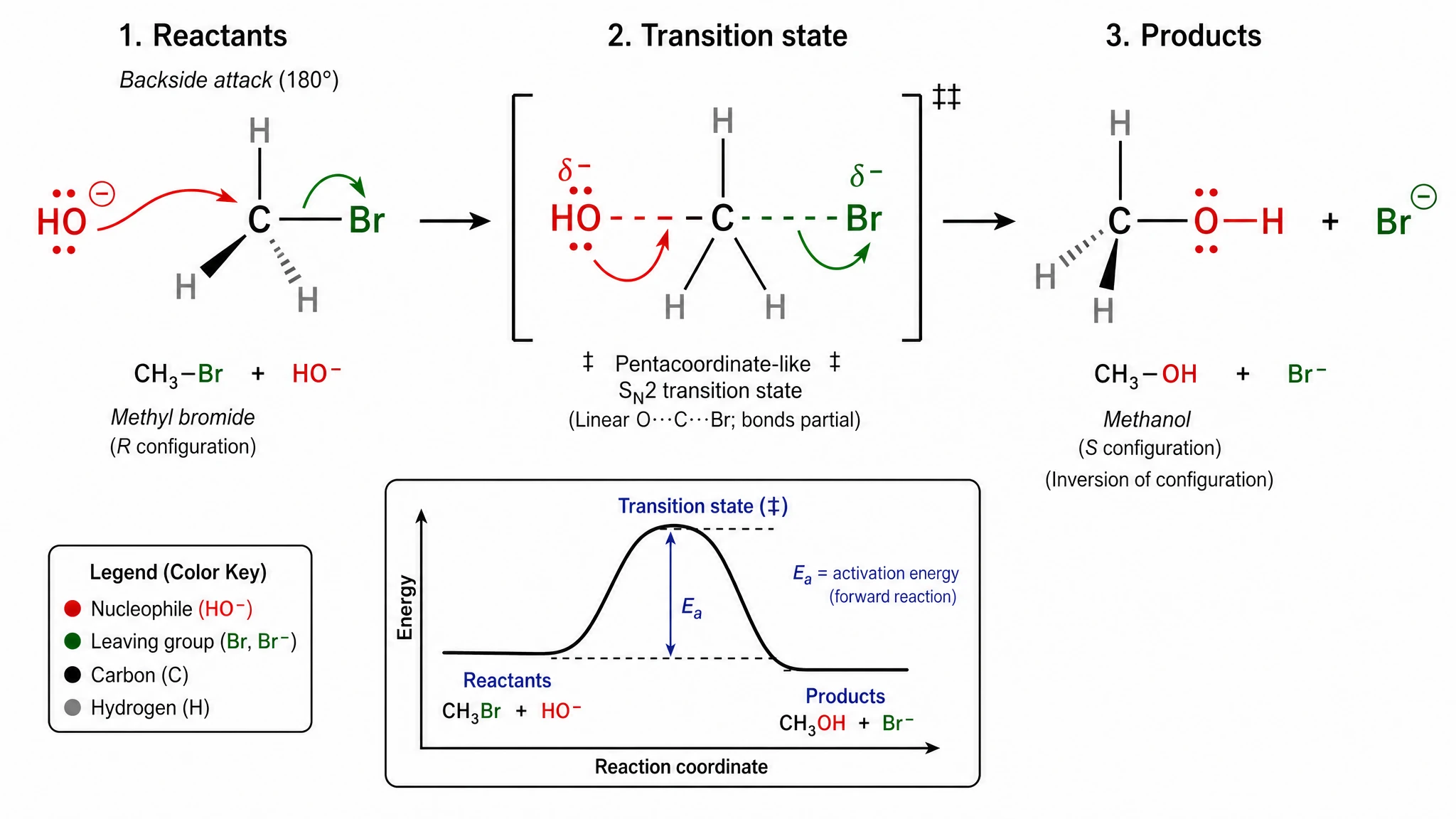
GPT Image 2 —— 化学规范全部渲染。得分 20/20。
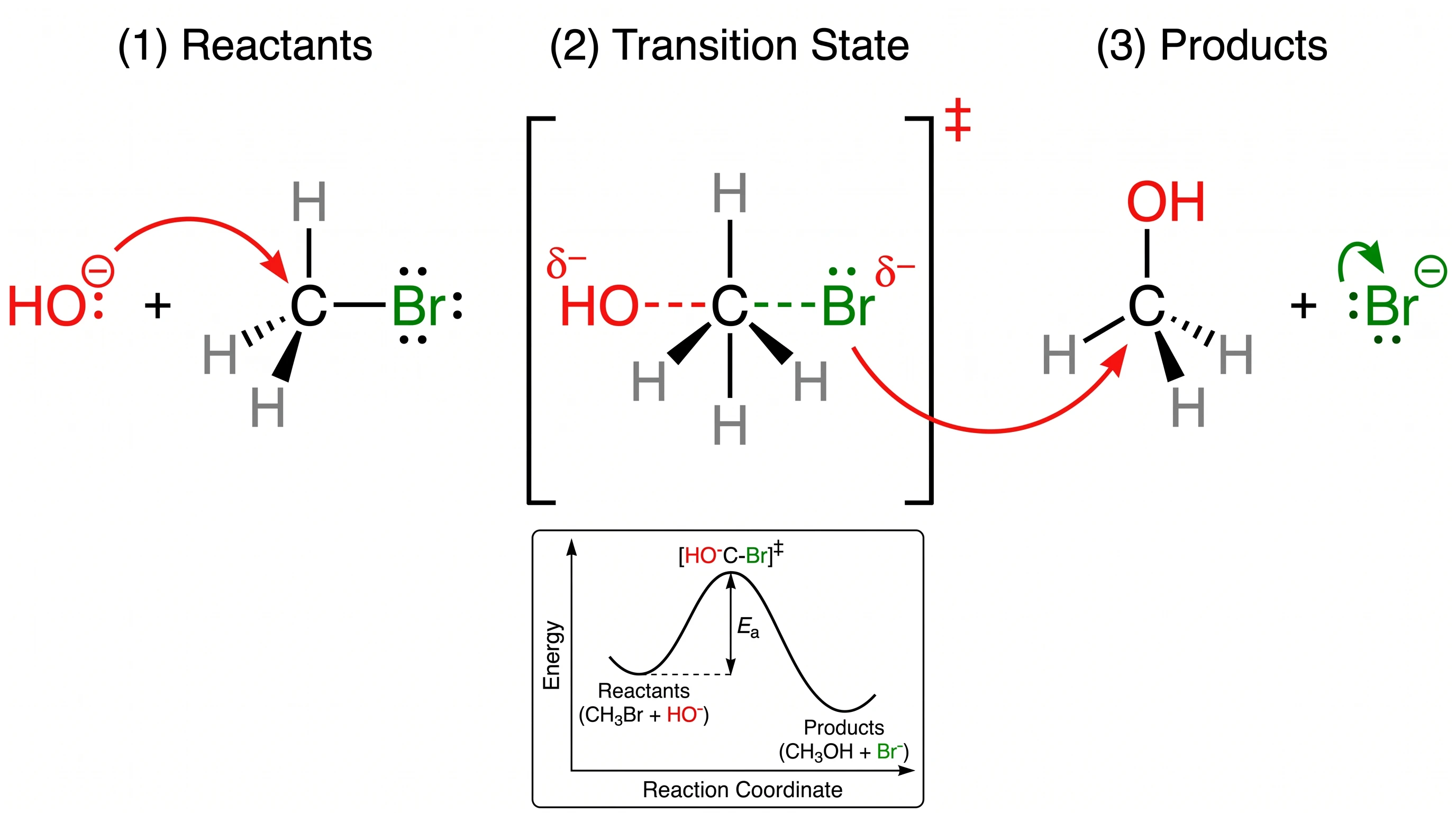
Nano Banana Pro —— 能识别为 SN2,但双匕首、R/S 立体标注、元素颜色图例都缺。得分 15/20——我们最大的单题分差。
发现 2:抽象 3D 拓扑可能让 Nano Banana Pro 翻车
这是整场盲测最意外的单一结果。提示词要求一张 3D 渲染的莫比乌斯环(带半扭转),加一个小 inset 对比普通可定向圆柱。GPT Image 2 完全按要求画了:主图是逼真的 3D Möbius 环,角落小图是圆柱并标"orientable cylinder, two distinct edges, two-sided surface",外加完整参数方程。
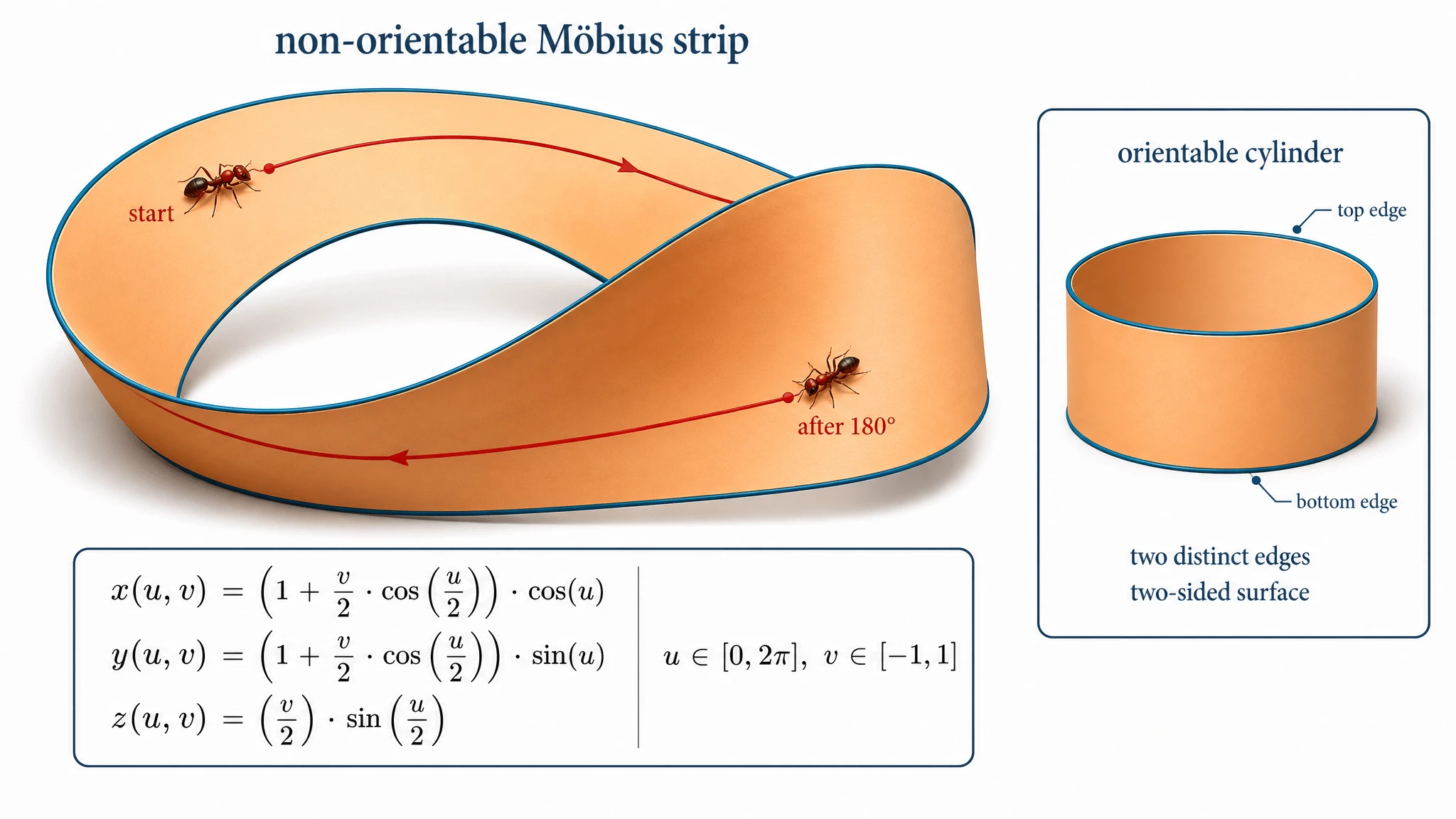
GPT Image 2 —— 可信的 3D 莫比乌斯环,半扭转清晰可见。圆柱在角落 inset 中,完全按 prompt 画。
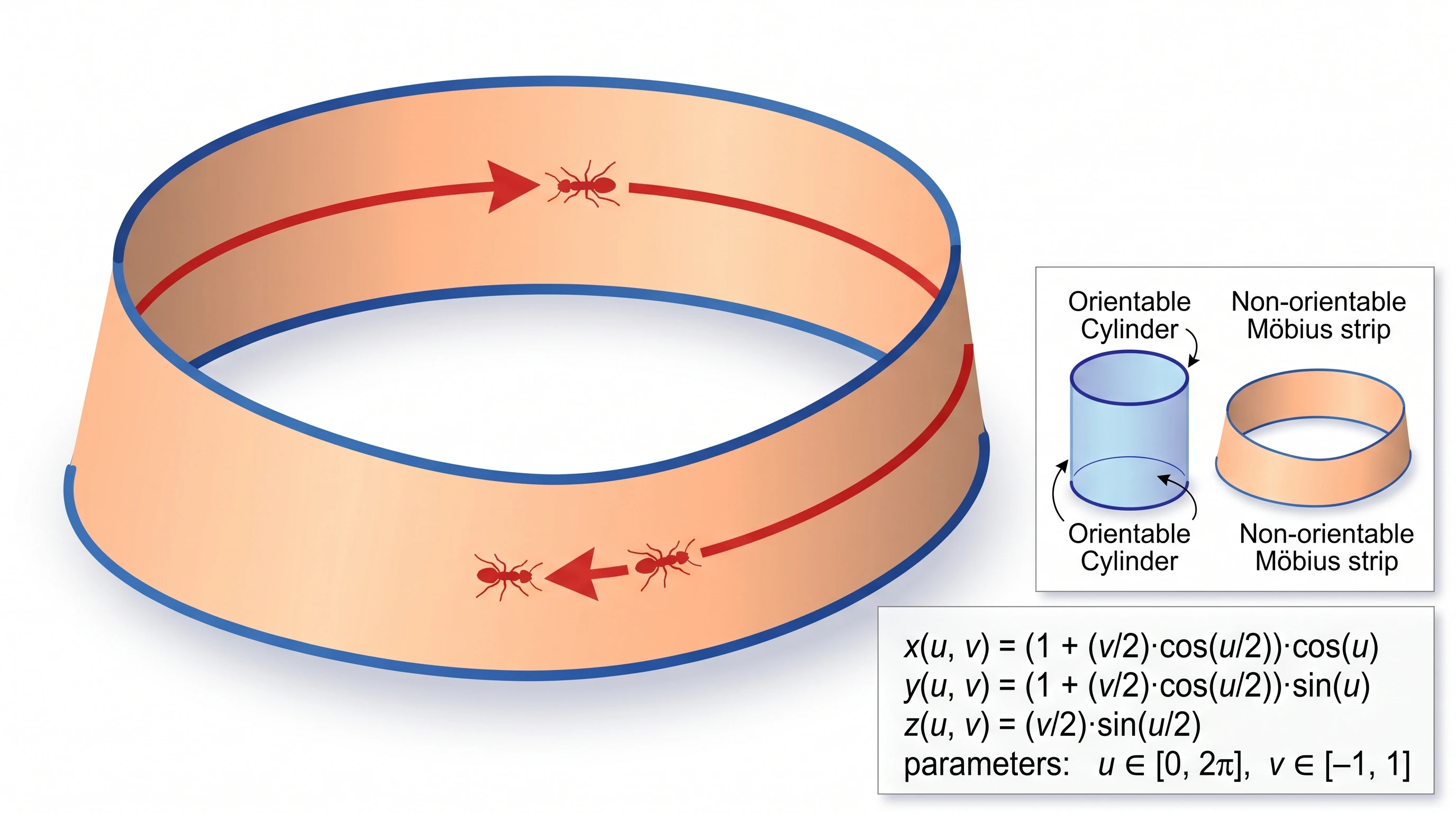
Nano Banana Pro —— 主图是普通圆柱不是莫比乌斯环。真正的 Möbius 环缩到角落 inset。概念渲染失败。
发现 3:会议幻灯片和海报默认选 Nano Banana Pro
最清晰的案例是光刻工艺图:Nano Banana Pro 主动做了一个我们没要求的构图选择——把 6 个工艺步骤拆成"上排详图 + 下排简化截面"两个 panel,正是 IEEE 半导体工艺教科书的呈现方式。最终成为整场评测分数最高的工程类图(19/20)。
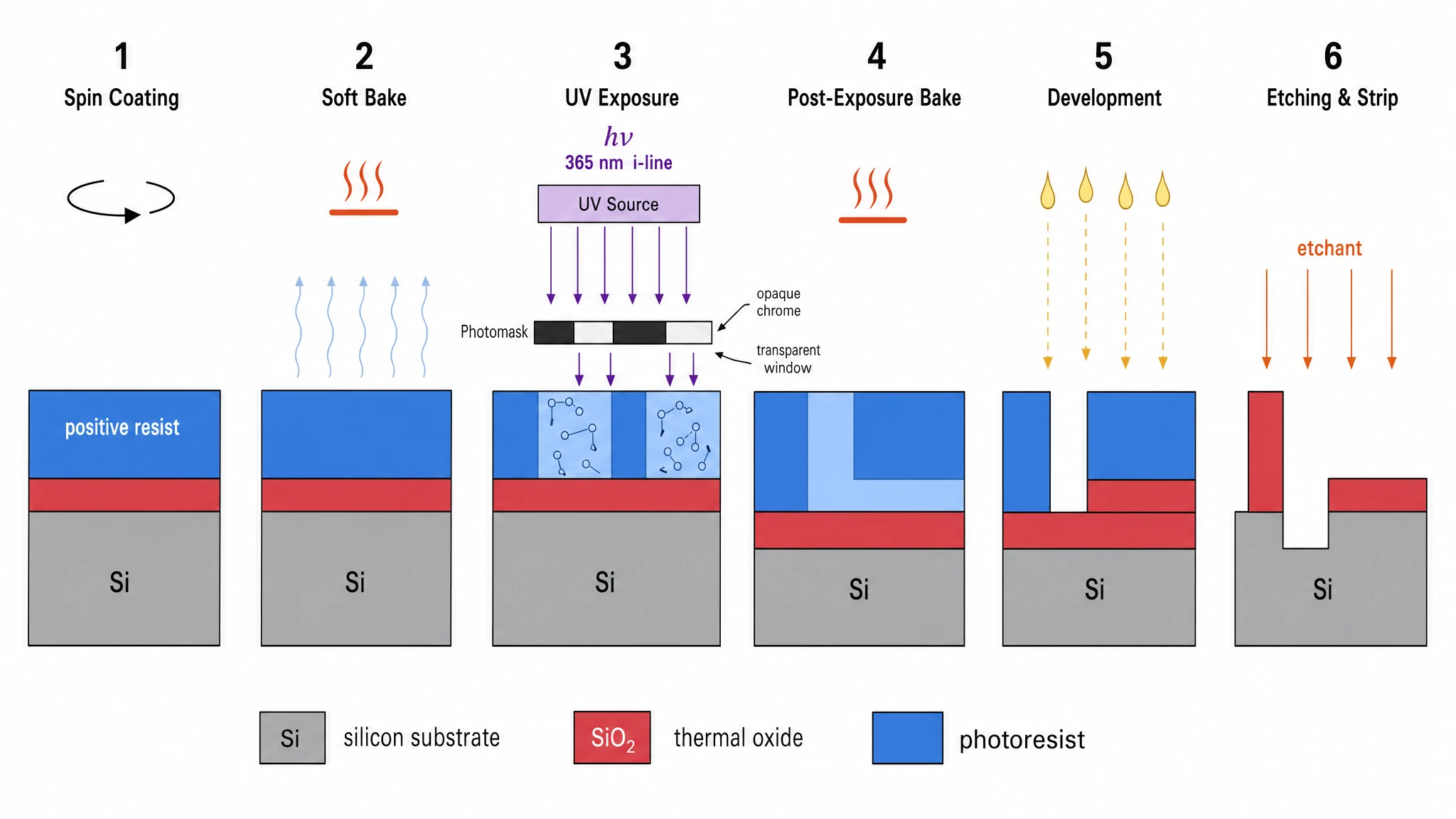
GPT Image 2 —— 单排 6-panel 流程,紧凑清晰。得分 17/20。
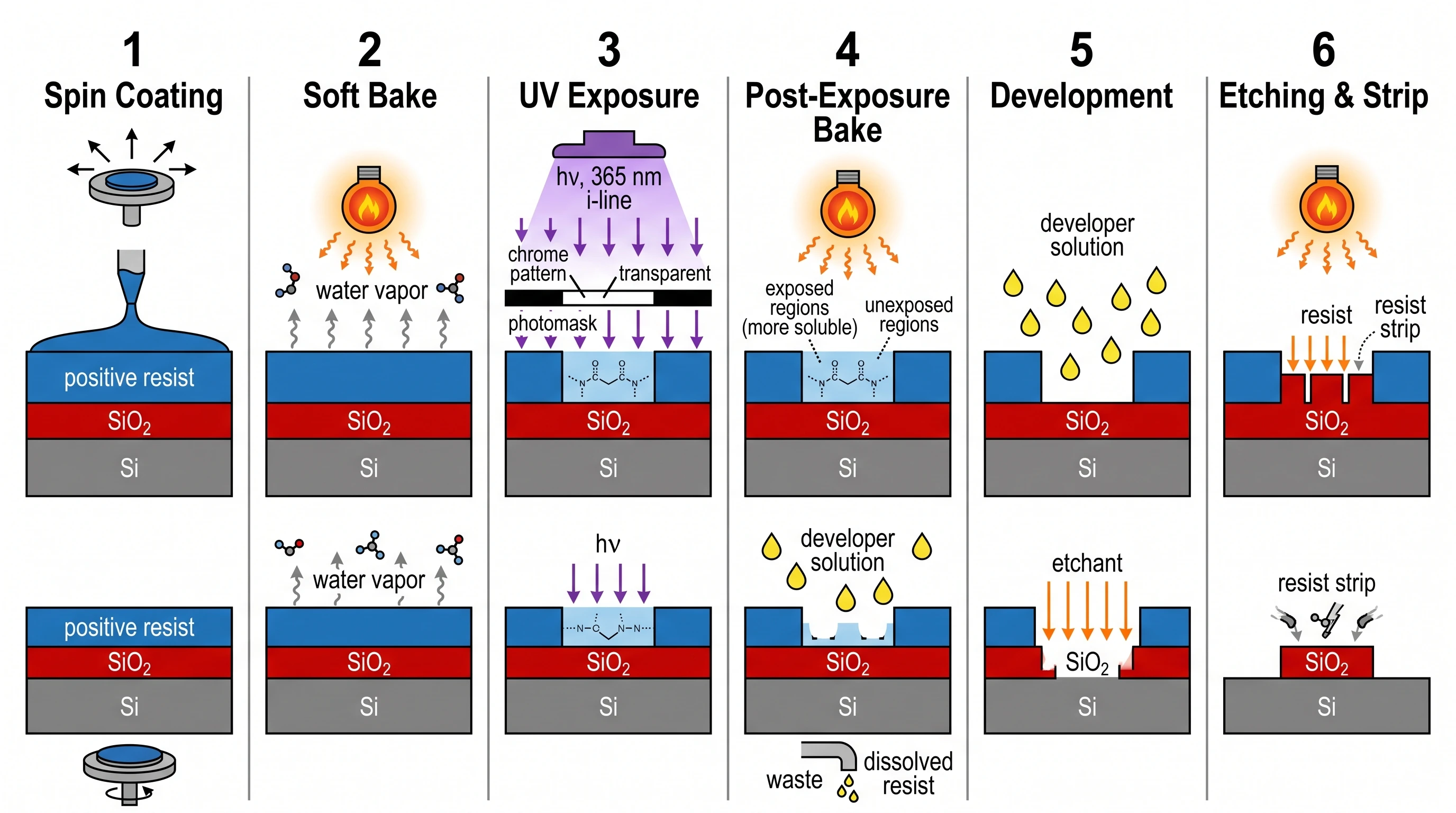
Nano Banana Pro —— 同样 6 步,但每步双 panel:上面详图、下面简化截面。这正是 IEEE 教科书呈现光刻的方式。得分 19/20——我们工程类图最高分。
按用途定制的决策框架
输出去同行评议期刊
- 化学、生化、有机化学论文 → GPT Image 2(决定性,见发现 1)
- 物理或带公式 / 坐标轴 / 比例尺的应用数学 → GPT Image 2(长 prompt 命中率优势)
- 拓扑、流形、抽象几何 → GPT Image 2(NBP 可能在概念上失败,见发现 2)
- 细胞生物学、信号通路、分子机制 → 都行,但 Nature Methods 和 Cell Reports Methods 的编辑有时偏好 NBP 的 BioRender 风
- 临床 / 解剖 → 都行;去 图库 浏览实例按视觉匹配挑选
输出去会议或演讲
- 10 分钟演讲幻灯片 → Nano Banana Pro(发现 3)
- 会议海报(A0 / A1) → Nano Banana Pro,除非图细节是关键(那种情况用 GPT Image 2 + 矢量画布 Vector Canvas 手动收尾)
- 组会 / journal club 讲解 → Nano Banana Pro 优先清晰度,再迭代
输出去网络
- Twitter / LinkedIn / 博文头图 → Nano Banana Pro(小缩略图下更干净)
- 课题组主页 → Nano Banana Pro
- 基金申请封面图 → 评审是技术评审 → GPT Image 2;评审是泛领域 → Nano Banana Pro
不确定时
五个反直觉发现
这些是盲测中颠覆我们事前预期的发现——开测前我们以为某些规律会出现,结果数据反过来了。如果你只能从这篇博客带走五个 takeaway,下面就是最反直觉、最值得记的那五条。每一条都直接基于 24 张图的实测数据,不是宏观感觉。
1. 更新更亮的模型不一定更强
开测前我们以为 GPT Image 2 会全面碾压(毕竟更新)。结果它没有。Nano Banana Pro 在 3 个 prompt 上完胜(CRISPR-Cas9、Transformer 架构、光刻流程)——而且赢得不轻松。教训:别假定营销声量更大的模型在你真正需要的图类型上一定赢。
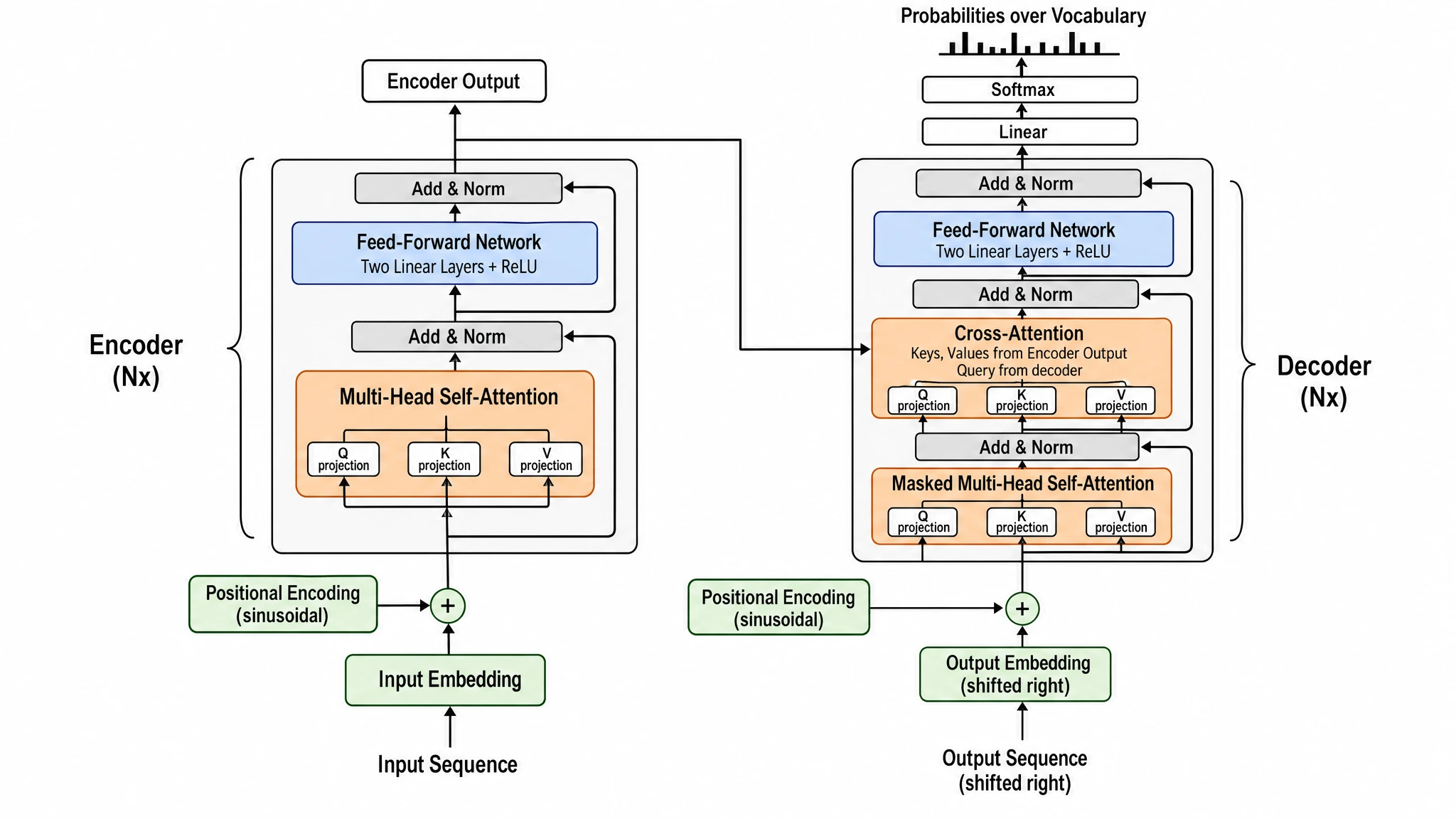
GPT Image 2 —— 每个组件都标得极精确("Two Linear Layers + ReLU"、"Keys, Values from Encoder Output, Query from decoder"、"sinusoidal" Position Encoding)。块状 2D。得分 16/20。
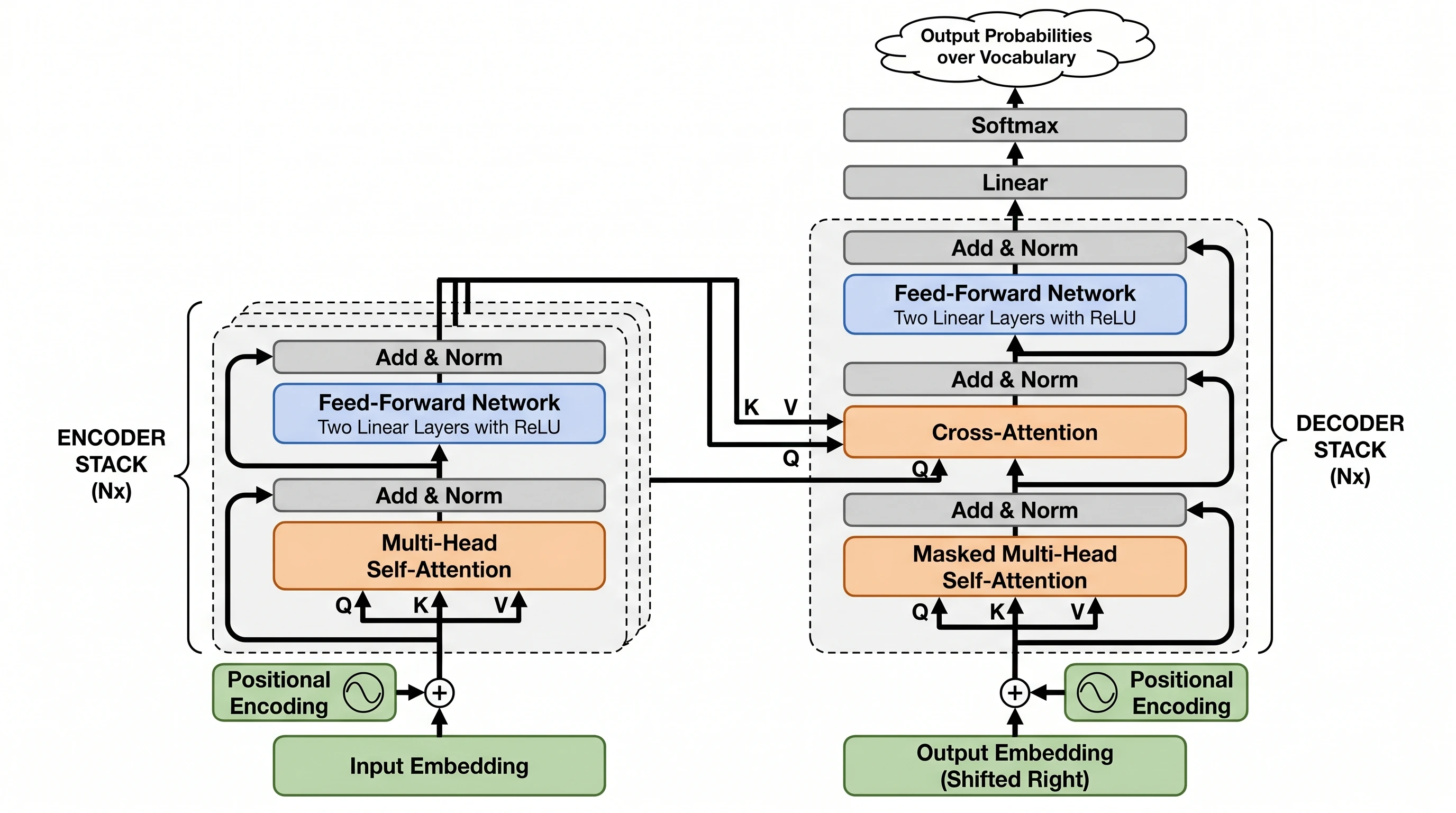
Nano Banana Pro —— 同样组件,但 encoder/decoder 渲染成视觉层叠的块(Nx 堆叠效果),K/V/Q 跨注意力箭头从 encoder 显式画到 decoder,Position Encoding 还给了一个小波形图标。结构直觉感胜出。得分 18/20。
2. 长 prompt 命中率差距是 13 个百分点,不是小事
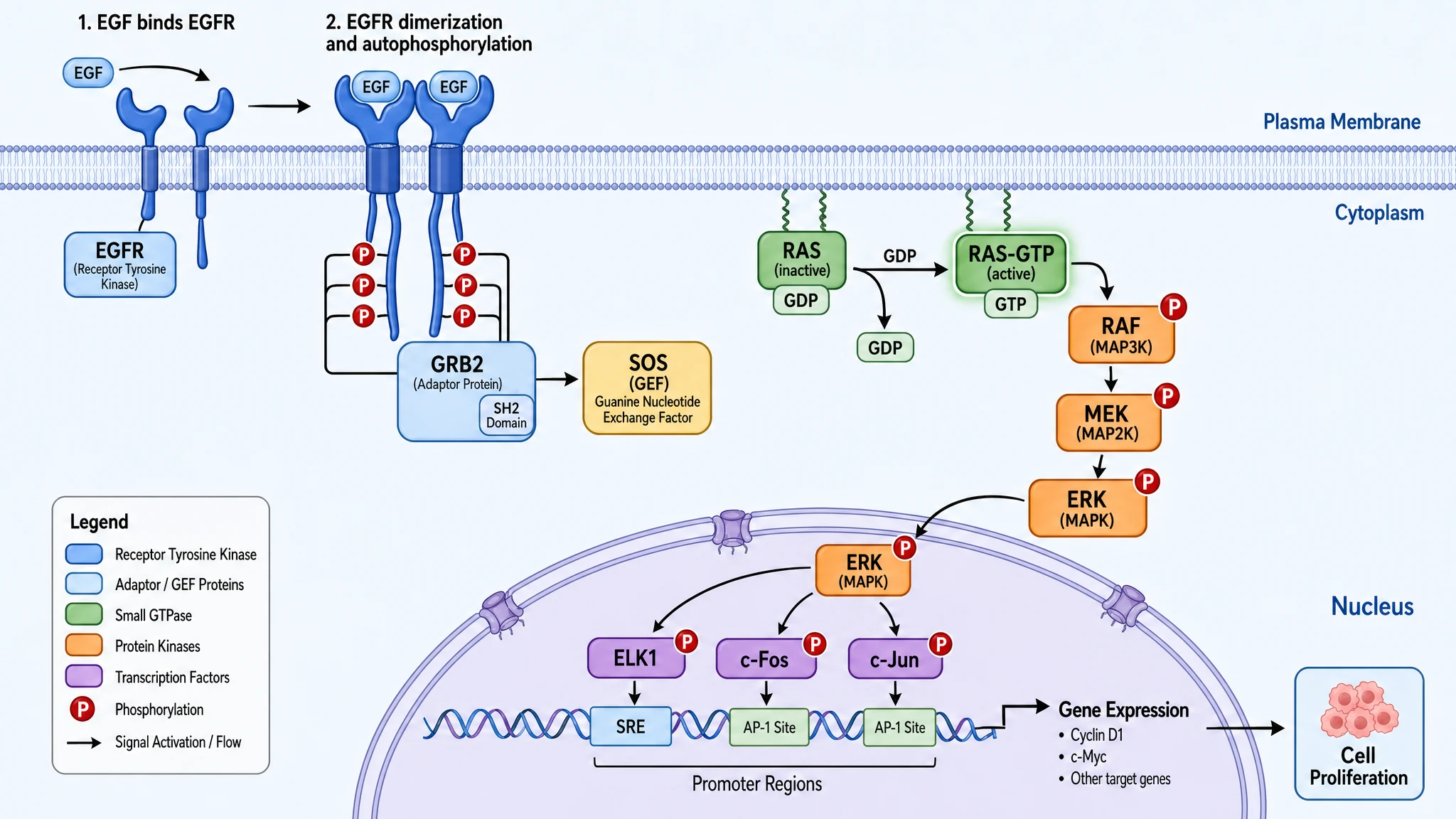
GPT Image 2 —— 完整信号级联含显式 GDP→GTP 交换、两步标号(1:EGF 结合,2:二聚 + 自磷酸化)、三个转录因子全部命名(ELK1 / c-Fos / c-Jun)、启动子区域分类(SRE / AP-1 Site)、具体目标基因(Cyclin D1, c-Myc)、6 类颜色图例。100% 提示词命中。
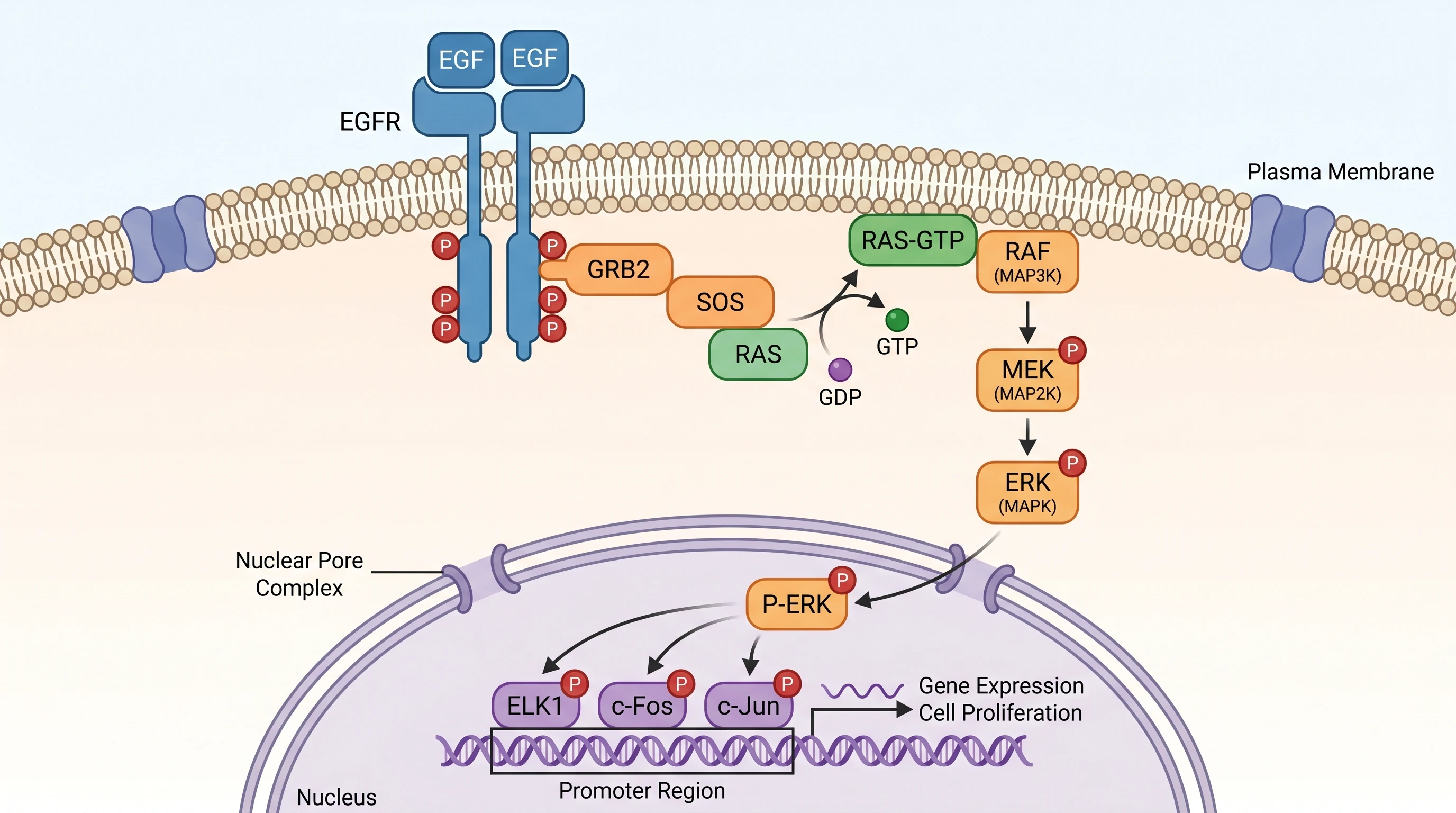
Nano Banana Pro —— 级联科学准确度持平,还加了一个解剖细节(Nuclear Pore Complex 显式画出),但缺颜色图例、SRE/AP-1 Site 启动子分类、具体目标基因(Cyclin D1, c-Myc)、SH2 Domain 标注。80% 命中。同样的生物学,更少的脚注。
3. "更听话"≠"更好看"
4. Nano Banana Pro 可能"幻觉"成完全错误的概念
5. 两款都能产出 Nature 封面级的图
板块构造测试两款都打了 19/20。三种板块边界并排、岩石圈与软流圈区分、地幔对流环、垂直深度坐标——这些地质剖面图看上去就像 National Geographic 或 USGS 出版物里的插图。在高端编辑级图上,两款的选择更像是审美偏好而非能力差距。黑洞吸积盘测试也印证了这一点——两款都能在硬核天体物理 prompt 上画出封面级图。
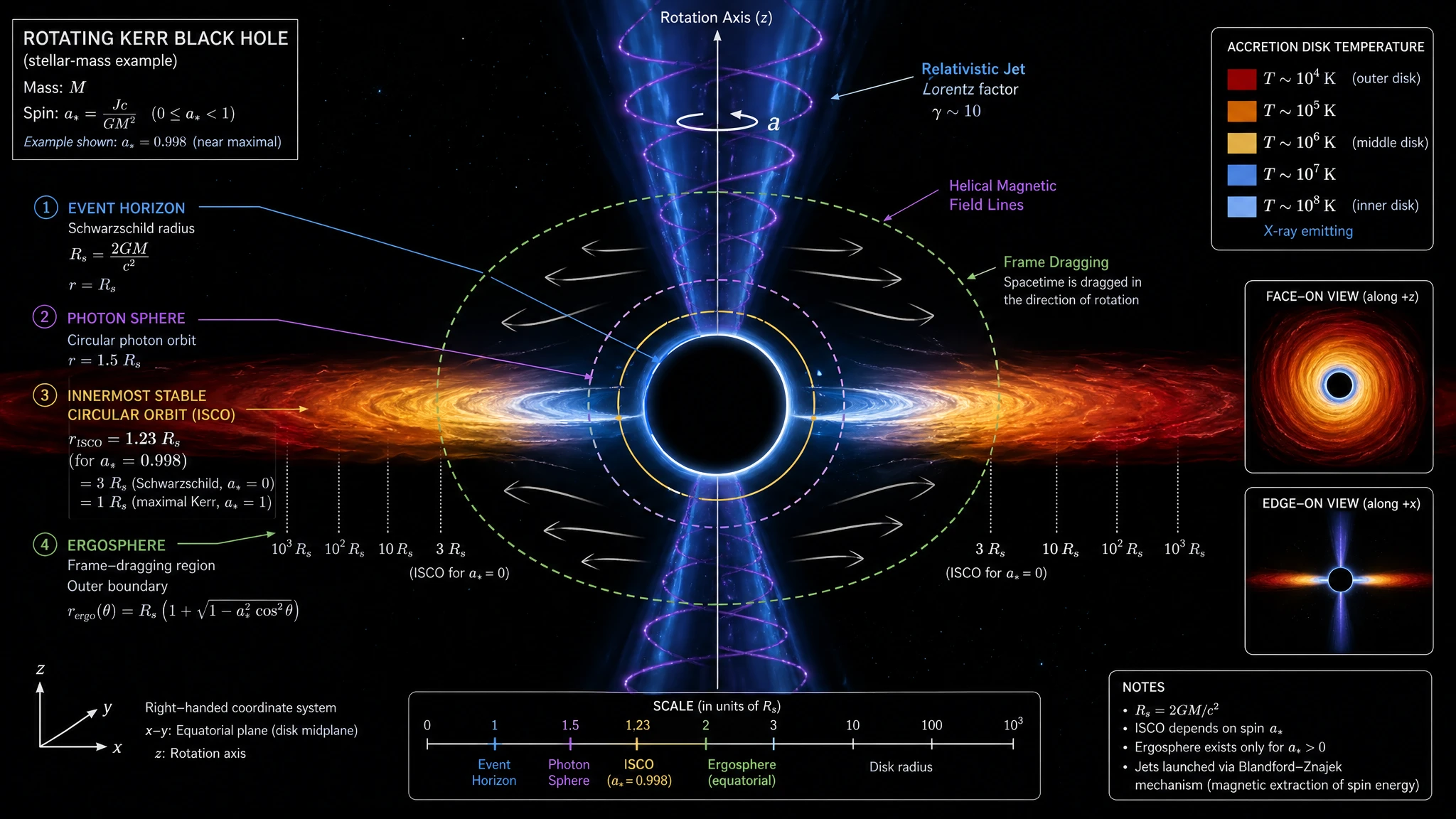
GPT Image 2 —— 天体物理期刊水准:标题"ROTATING KERR BLACK HOLE"、4 个边界标注(Event Horizon、Photon Sphere 1.5 Rs、ISCO、Ergosphere)、吸积盘温度梯度(10⁴ K → 10⁸ K)含侧边图例、螺旋磁场线穿过喷流、frame-dragging 箭头、右手坐标系、多视角 inset(face-on + edge-on)、Notes box 含 Blandford-Znajek 机制引用。
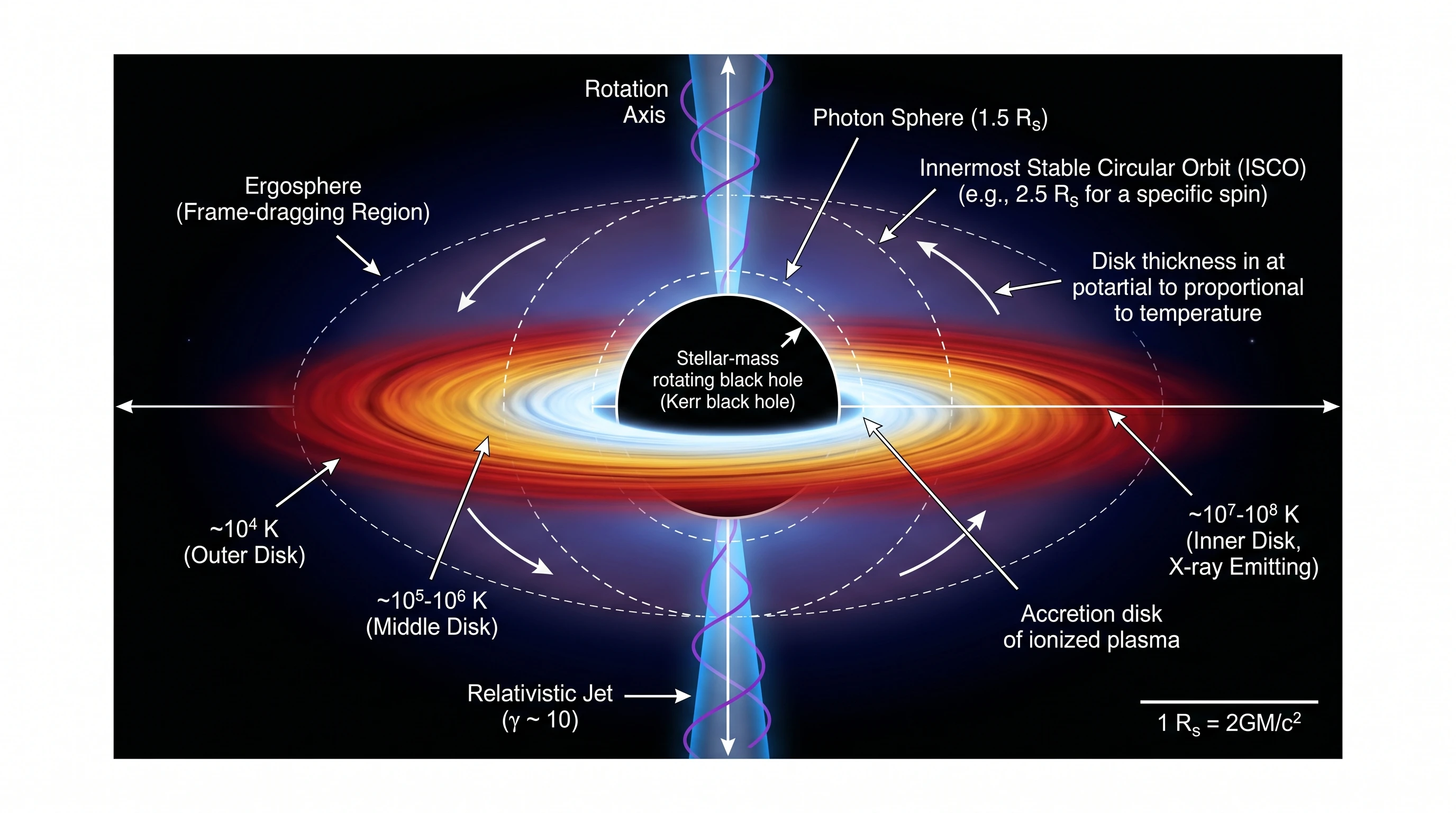
Nano Banana Pro —— 同样科学准确度,同样按颜色编码温度梯度,吸积盘厚度显式标注与温度成比例。标注稍少(无坐标系、无多视角 inset、无磁场标签),但视觉上仍冲击力十足,足以登上杂志封面。注意主体周围有意保留的负空间——Nano Banana Pro 在天体物理类 prompt 上倾向给主体留呼吸空间,与上方 GPT Image 2 那张信息密集的构图形成鲜明对比。这本身就是值得并排观察的构图哲学差异。
什么时候同时跑两款
有三种场景下,对同一个 prompt 同时跑两款模型是值得的——不是浪费积分,而是真正能省下事后修改的成本。下面三类情境里,并排生成挑赢的是合理操作;其他 80% 的图按本文上面的决策框架定默认模型,一次出图就够。
- 高 stakes 图:论文 Figure 1、基金申请封面图、答辩幻灯片。多生成一次的成本是两轮积分;选错模型的成本是几天的修改或基金被拒。
- 不熟悉或抽象的概念:拓扑、高等数学、基础物理,或任何你不确定两款是否见过足够训练数据的领域。肉眼复核很重要。
- 风格 A/B 测试:当你不确定受众更喜欢 GPT Image 2 的密集风还是 Nano Banana Pro 的编辑风。生成两版给同事看,按反应挑选。
对于例行的 80% 的图——明确科研规格、常见主题、低歧义——按上面框架定个默认模型,别浪费积分。对于 20% 高代价错图,跑两款。
我们为什么相信这份结论
这份指南基于一份专门为它做的盲测:12 个科研提示词、覆盖 10 学科,通过 Kie.ai(SciFig 生产环境同一供应商)API 直连,每张图按 6 个维度打分(含明确 rubric 和评分理由)。两款模型在同一天、同一参数下测试:16:9 比例、2K 分辨率。
/inspiration?model=gpt-image-2 和 /inspiration?model=nano-banana-pro。完整评分矩阵在姊妹评测篇里。如果你复测某个 prompt 得到不同结果,请告诉我们——那种信息很有价值。 透明度是有意为之:OpenAI 和 Google 的市场宣传无法验证,可复现的并排测试是 2026 年评测旗舰模型唯一诚实的方法。提示