La vraie question derrière « lequel est le meilleur »
Avant les conclusions, l'antisèche pour ce à quoi chaque phare est destiné :
| Aspect | GPT Image 2 | Nano Banana Pro |
|---|---|---|
| Parent | OpenAI | Google (Gemini 3) |
| Conçu pour | Figures riches en détails avec spécifications strictes | Figures de style éditorial avec accent sur la composition |
| Gagne sur | Rigueur chimique, formules mathématiques, topologie abstraite, fidélité aux prompts longs | Lisibilité, raffinement esthétique, diagrammes structurels (CS / processus / mécanisme) |
| Perd sur | La densité d'information peut encombrer | La fidélité aux prompts longs chute de 13 points sur les spécifications complexes ; rares erreurs de rendu conceptuel |
| Par défaut pour | Soumission à une revue | Diapositives / posters / web |
| Dans SciFig | /models/gpt-image-2 | /models/nano-banana-pro |
Trois conclusions décisives (et pourquoi elles s'appliquent probablement à vous)
Nous avons extrait trois conclusions du benchmark de 24 figures qui devraient changer le modèle vers lequel vous vous tournez par défaut. Elles sont décisives au sens où l'écart de score est suffisamment grand pour qu'un coup de pile ou face soit erroné.
Conclusion 1 : Les articles de chimie devraient utiliser GPT Image 2 (pas même proche)
‡ sur l'état de transition, étiqueté les configurations stéréochimiques R et S sur le réactif et le produit, rendu le carbone pentacoordonné avec trois hydrogènes plats dans le plan trigonal, inclus un diagramme énergétique complet en encart avec l'énergie d'activation Ea étiquetée, et ajouté une légende quatre couleurs identifiant nucléophile / groupe partant / carbone / hydrogène.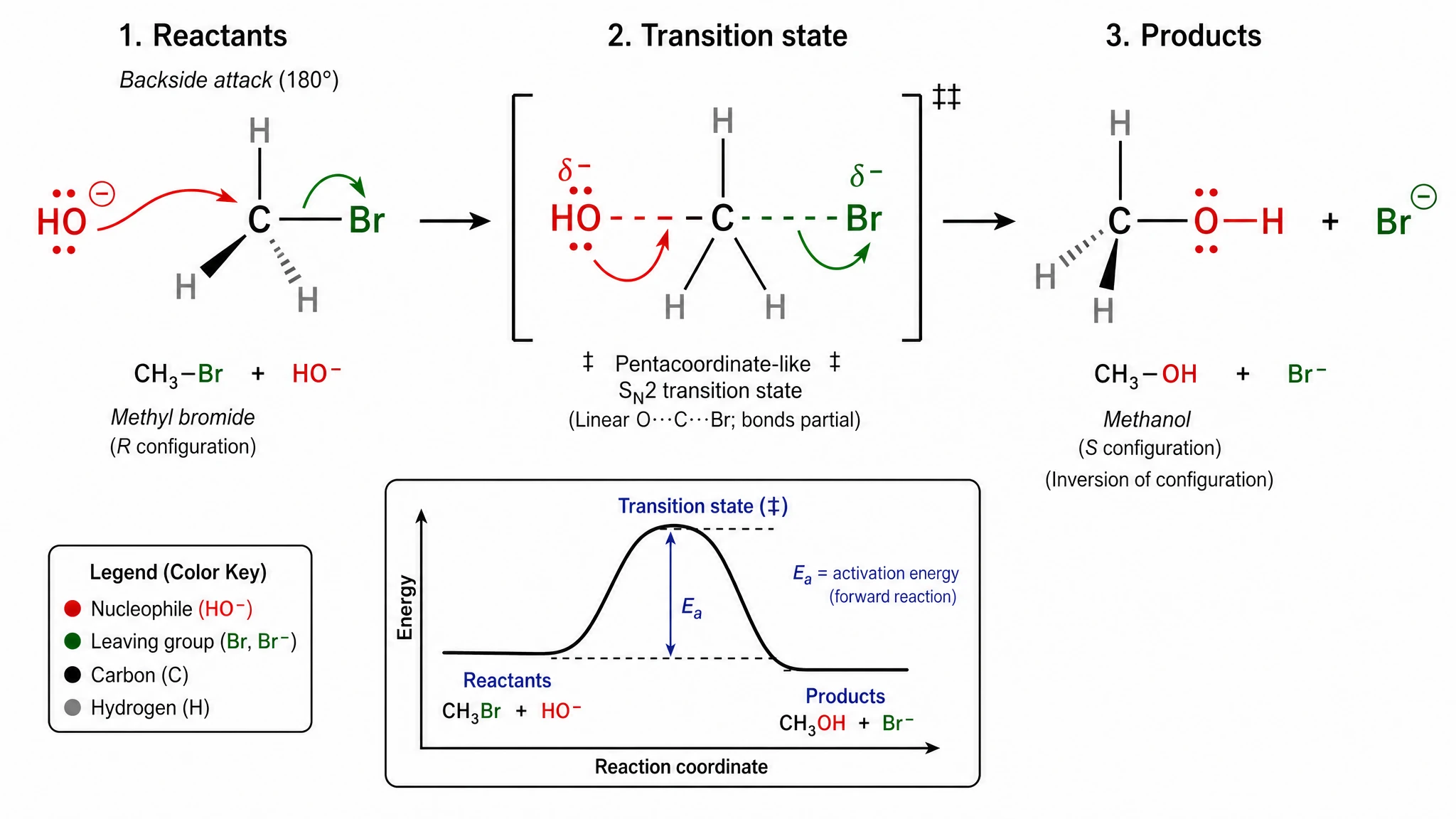
GPT Image 2 — chaque convention chimique standard rendue. Score 20/20.
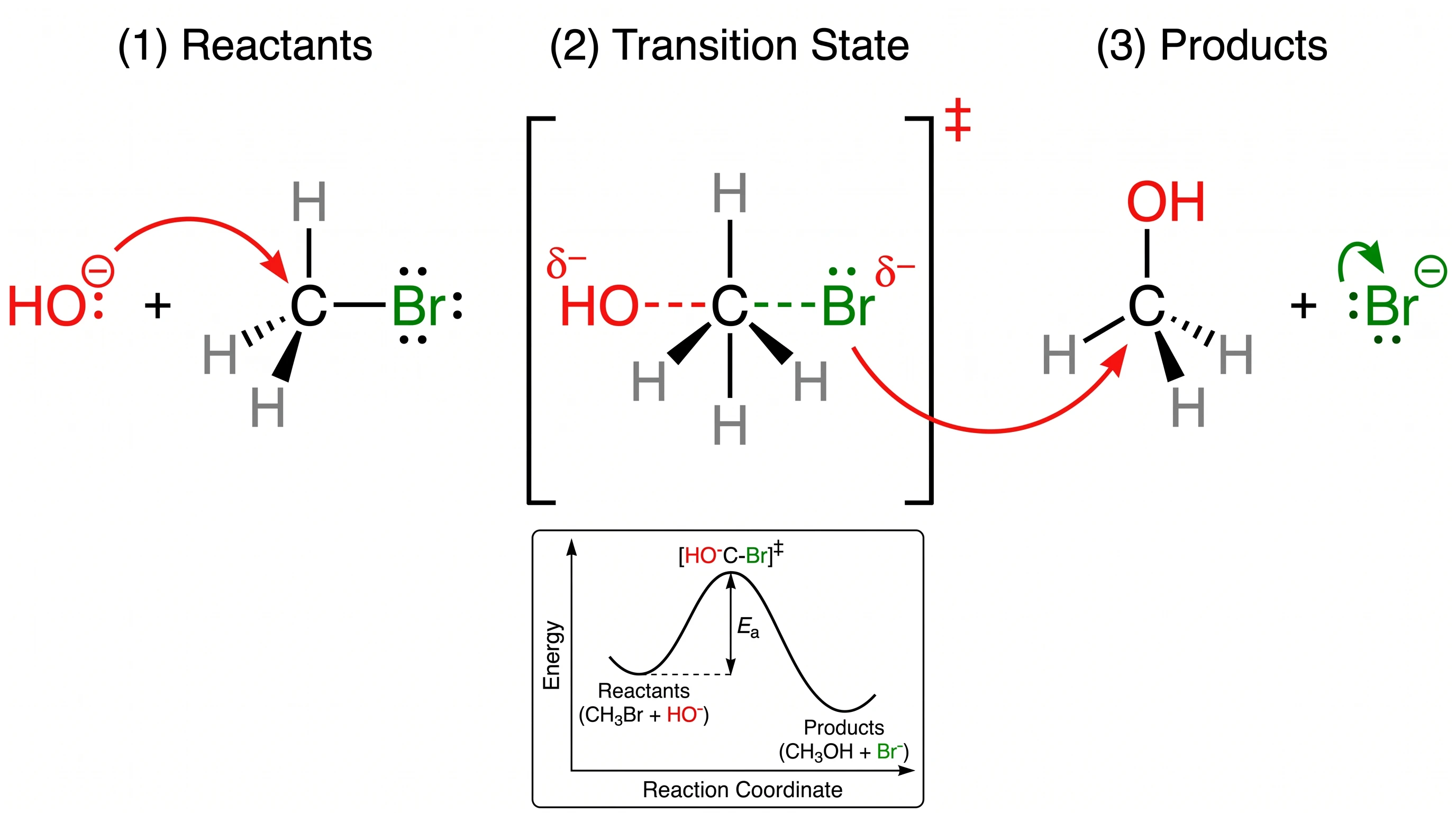
Nano Banana Pro — mécanisme reconnaissable mais la double-dague, la stéréochimie R/S et la légende d'éléments en couleur sont toutes manquantes. Score 15/20 — notre plus grand écart sur un seul prompt.
Conclusion 2 : La topologie 3D abstraite peut casser Nano Banana Pro
C'était le résultat le plus surprenant de notre benchmark. Le prompt demandait un ruban de Möbius rendu en 3D avec un demi-tour, accompagné d'un petit encart le comparant à un cylindre orientable régulier. GPT Image 2 a livré exactement cela : un ruban de Möbius 3D crédible sur la figure principale, un petit cylindre dans le coin étiqueté « cylindre orientable, deux arêtes distinctes, surface à deux côtés », plus l'équation paramétrique complète rendue comme un bloc mathématique.
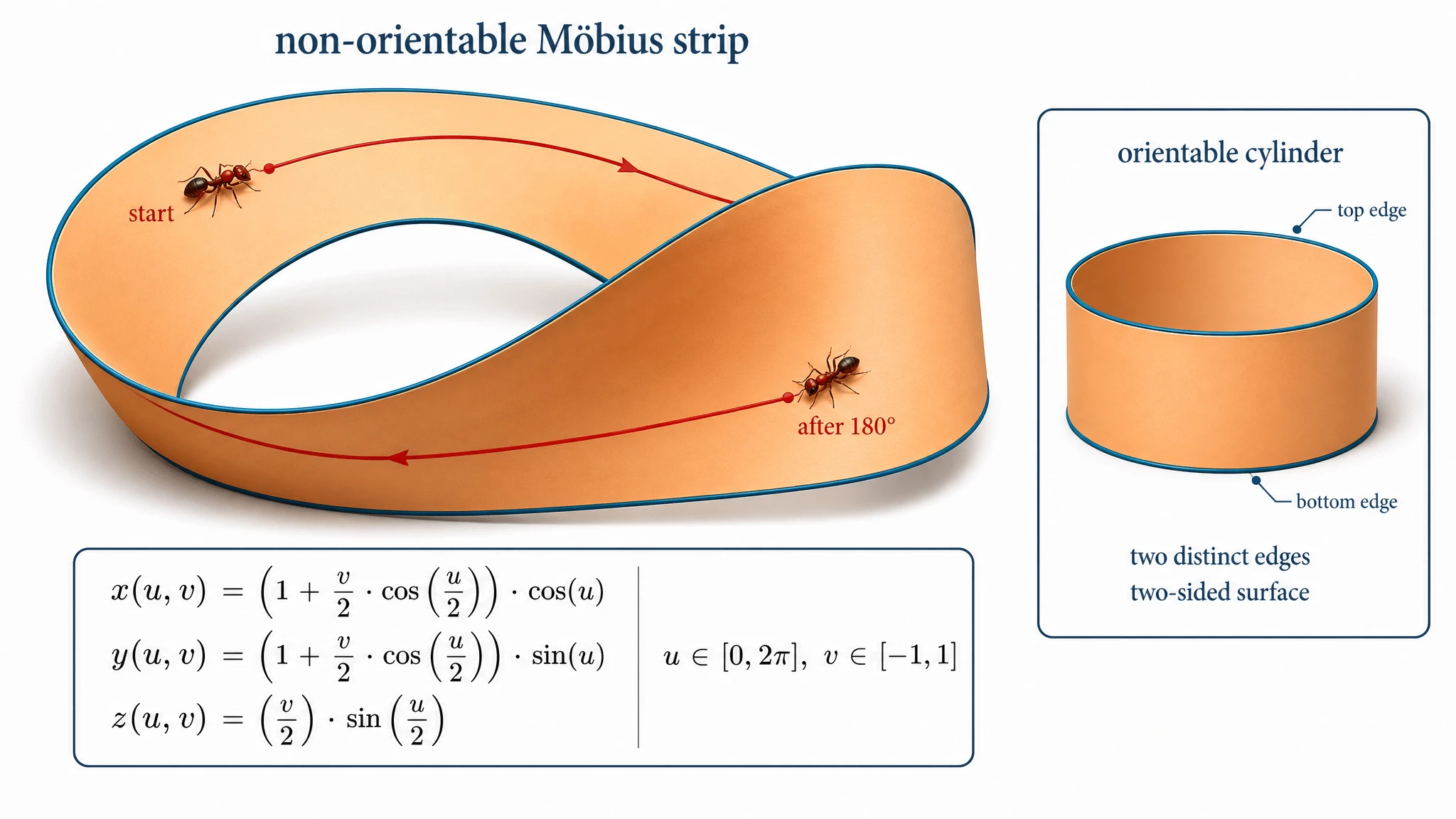
GPT Image 2 — ruban de Möbius 3D crédible avec le demi-tour clairement visible. Le cylindre est dans l'encart en coin, exactement comme le prompt le demandait.
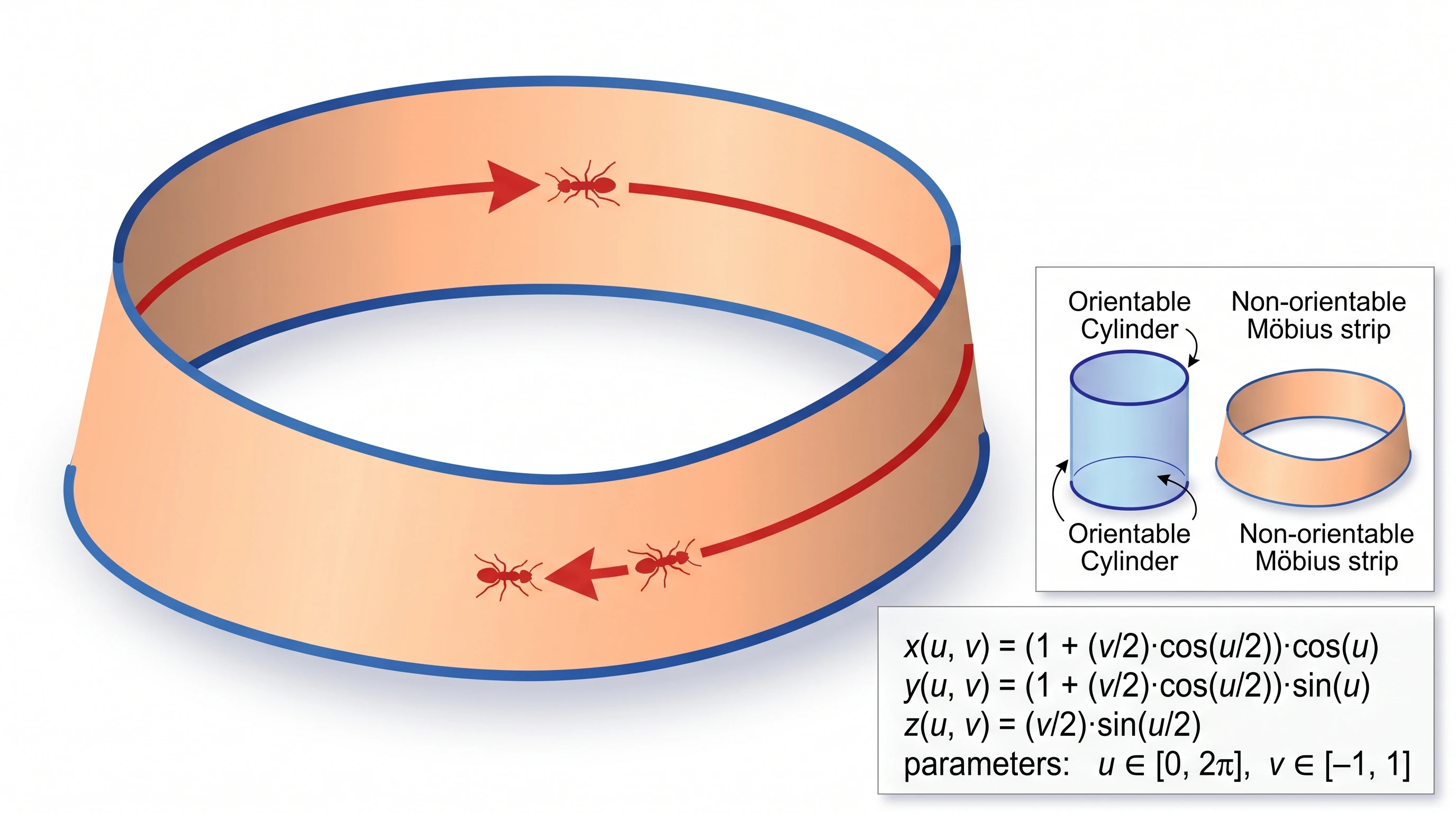
Nano Banana Pro — la figure principale est un cylindre simple, pas un ruban de Möbius. Le véritable ruban de Möbius est rétréci dans un minuscule encart en coin. Échec de rendu conceptuel.
Conclusion 3 : Les diapositives de conférence et posters devraient choisir Nano Banana Pro par défaut
Le cas le plus clair était la figure de processus de photolithographie : Nano Banana Pro a fait un choix de composition créatif que nous n'avions pas demandé, divisant chacune des 6 étapes du processus en un panneau « vue détaillée » au-dessus et un panneau « coupe simplifiée » en dessous — exactement la façon dont les manuels IEEE présentent les processus de semi-conducteurs. Le résultat a été la figure d'ingénierie la mieux notée du benchmark (19/20).
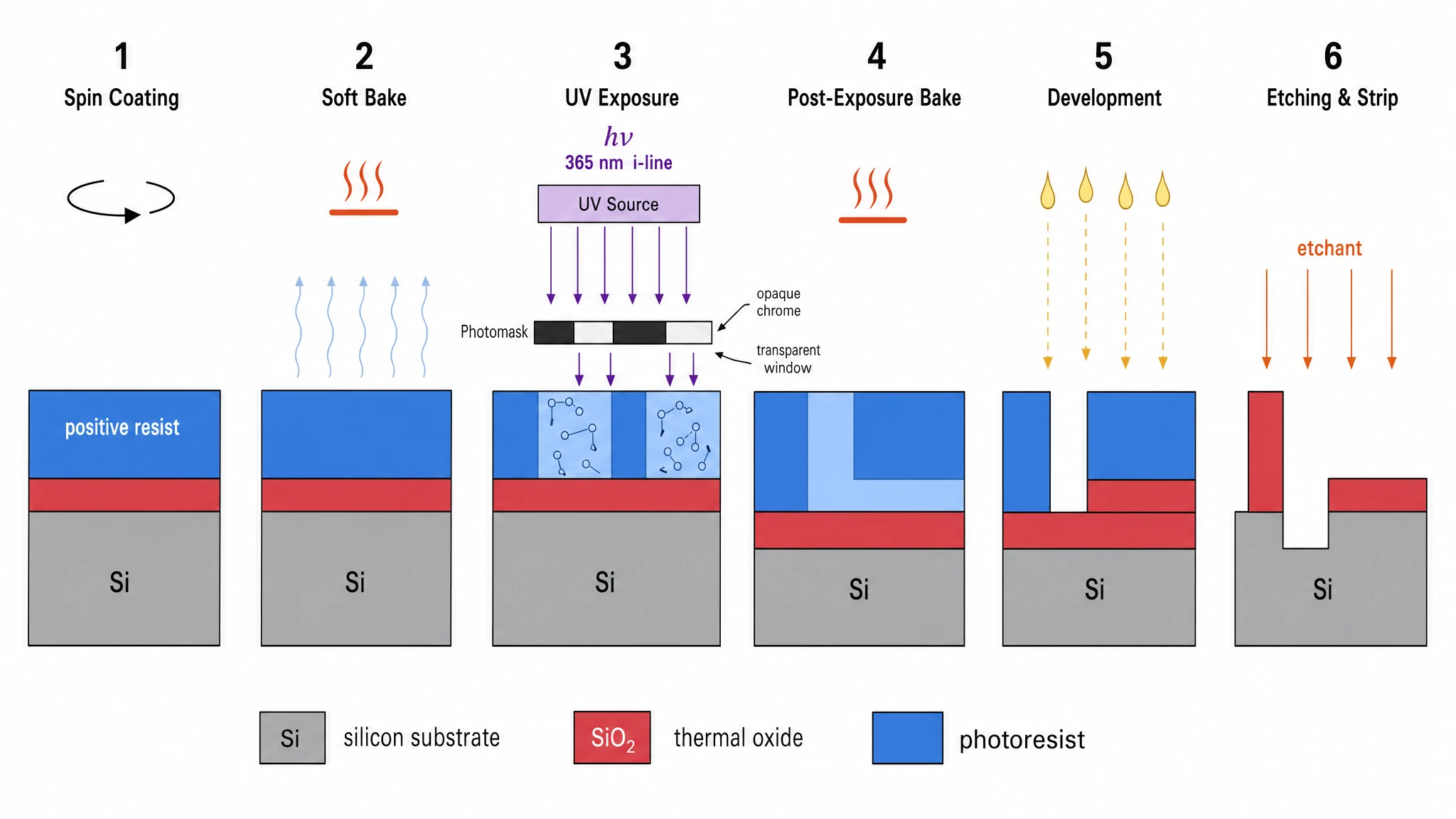
GPT Image 2 — séquence de 6 panneaux sur une seule rangée, compacte et claire. Score 17/20.
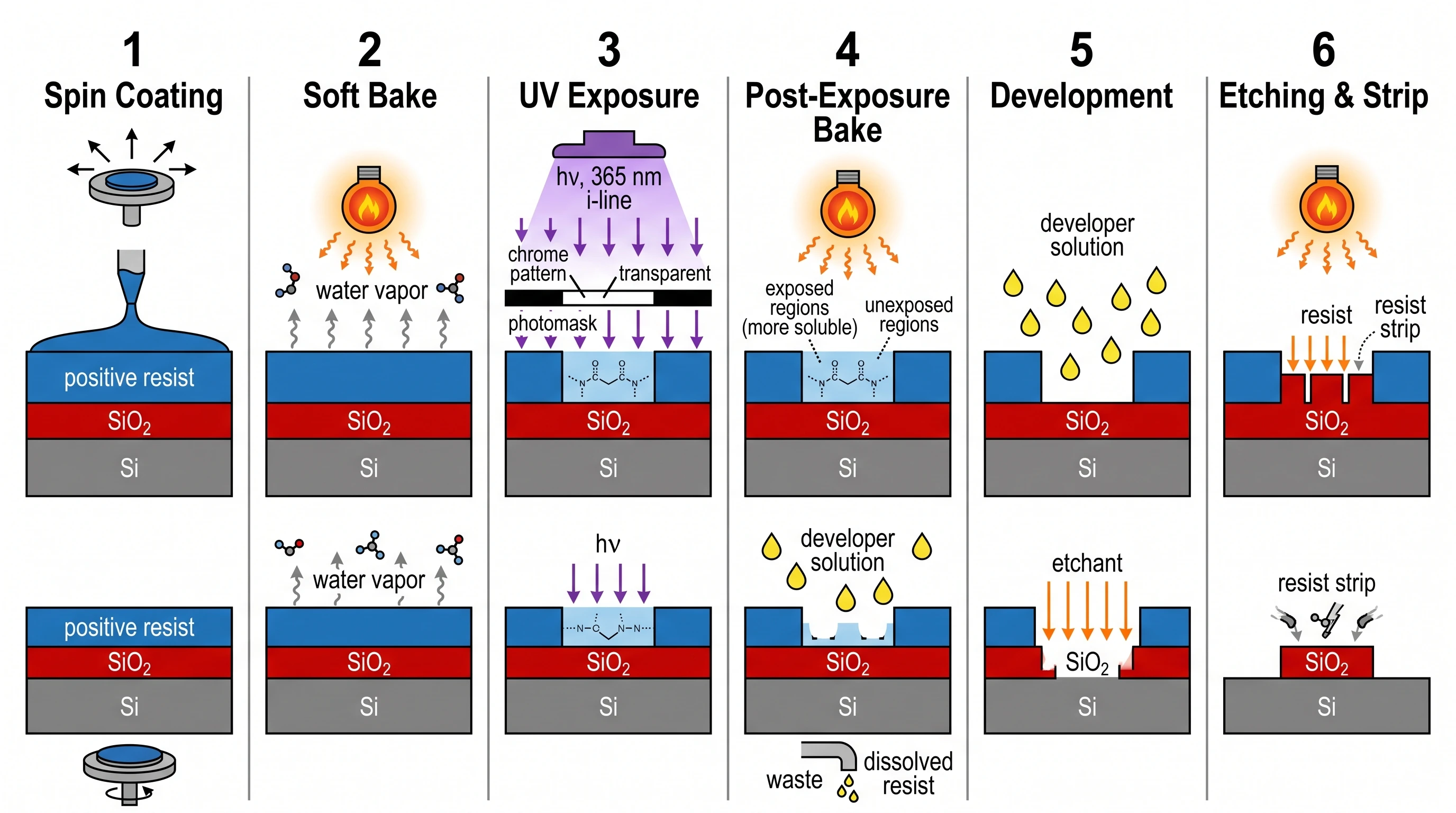
Nano Banana Pro — mêmes 6 étapes mais chacune rendue en double panneau : vue détaillée en haut, coupe simplifiée en bas. C'est ainsi que les manuels IEEE présentent réellement la photolithographie. Score 19/20 — notre figure d'ingénierie la mieux notée.
Voyez la génération de figures scientifiques par IA en action
Observez comment les chercheurs créent des figures scientifiques prêtes à publier à partir de descriptions textuelles.
Explorer l'outilUn cadre de décision adapté à votre sortie
Si votre sortie va vers une revue à comité de lecture
- Articles de chimie, biochimie, chimie organique → GPT Image 2 (décisif, voir Conclusion 1)
- Physique ou mathématiques appliquées avec formules, axes, barres d'échelle → GPT Image 2 (fidélité aux prompts longs)
- Topologie, variétés, géométrie abstraite → GPT Image 2 (NBP peut échouer conceptuellement, voir Conclusion 2)
- Biologie cellulaire, voies de signalisation, mécanismes moléculaires → l'un ou l'autre, mais le style BioRender de NBP est parfois préféré par les éditeurs de Nature Methods et Cell Reports Methods
- Clinique / anatomie → l'un ou l'autre ; consultez notre galerie d'exemples pour des sorties comparables et choisissez par adéquation visuelle
Si votre sortie va vers une conférence ou un exposé
- Présentation pour un exposé de 10 minutes → Nano Banana Pro (Conclusion 3)
- Poster de conférence (taille A0 / A1) → Nano Banana Pro sauf si la figure est critique en détails (auquel cas GPT Image 2 + nettoyage manuel dans Vector Canvas)
- Réunion de laboratoire / explication de journal club → Nano Banana Pro pour la clarté, puis itérer
Si votre sortie va sur le web
- En-tête Twitter / LinkedIn / article de blog → Nano Banana Pro (plus net aux petites tailles de vignette)
- Page d'accueil de laboratoire universitaire → Nano Banana Pro
- Image de couverture de proposition de subvention → GPT Image 2 si l'évaluateur de l'agence est technique ; Nano Banana Pro si l'évaluateur est un public plus large
Si vous n'êtes pas sûr
Créez des figures scientifiques maintenant
Décrivez votre figure scientifique en langage naturel — obtenez des illustrations prêtes à publier en quelques minutes.
Essayer gratuitementCinq découvertes contre-intuitives
Ce sont les conclusions de notre benchmark qui ont contredit nos attentes initiales.
1. Le modèle plus récent et plus tape-à-l'œil n'est pas automatiquement meilleur
En entrant, nous nous attendions à ce que GPT Image 2 domine tout parce qu'il s'agit de la version la plus récente. Ce n'a pas été le cas. Nano Banana Pro a remporté trois prompts sans appel (CRISPR-Cas9, architecture Transformer, photolithographie) — et les victoires n'étaient pas serrées. La leçon : ne supposez pas que le modèle avec le marketing le plus bruyant gagne sur le type de figure dont vous avez réellement besoin.
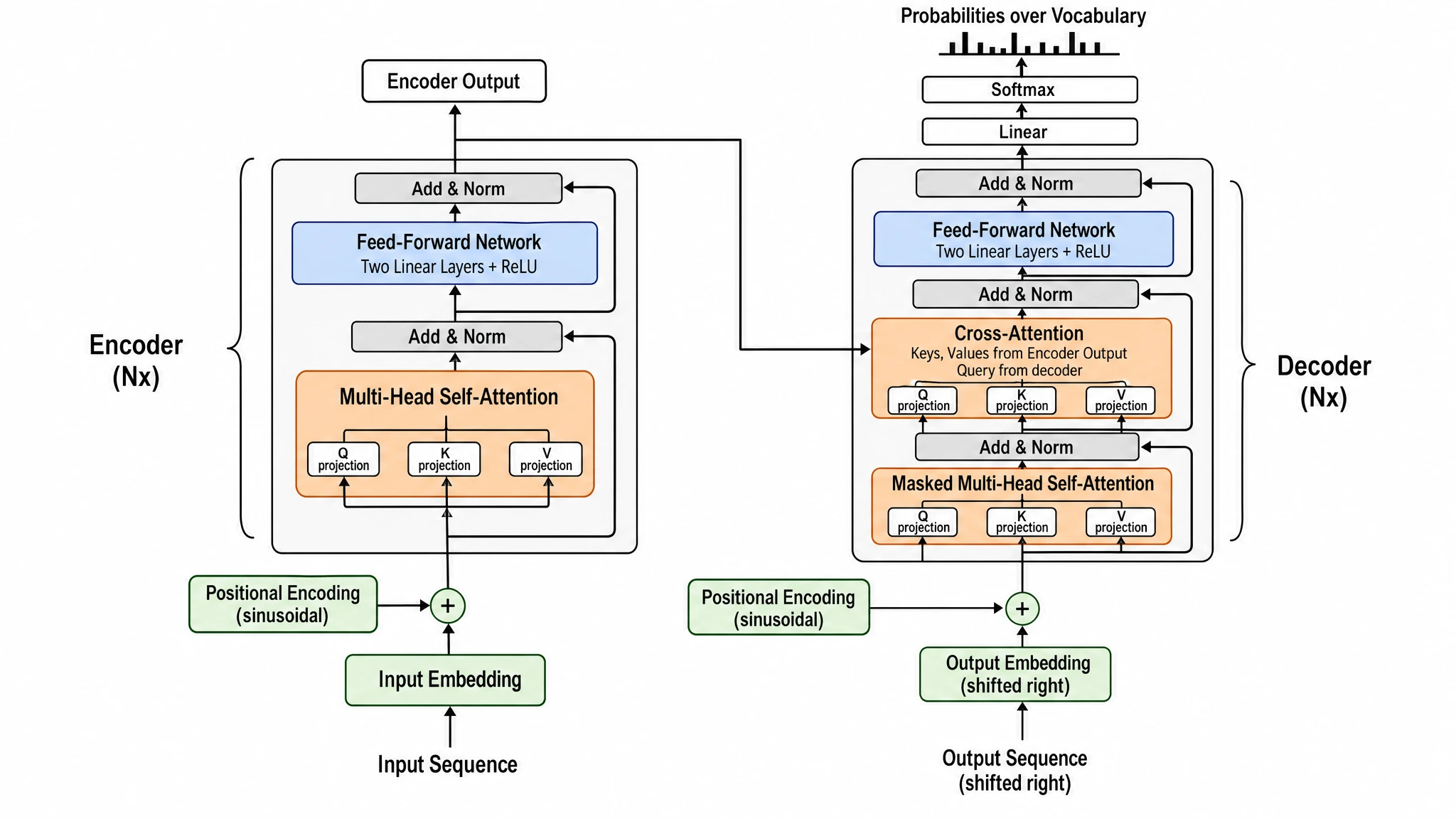
GPT Image 2 — chaque composant étiqueté avec une grande précision (« Two Linear Layers + ReLU », « Keys, Values from Encoder Output, Query from decoder », encodage positionnel « sinusoïdal »). Blocs 2D plats. Score 16/20.
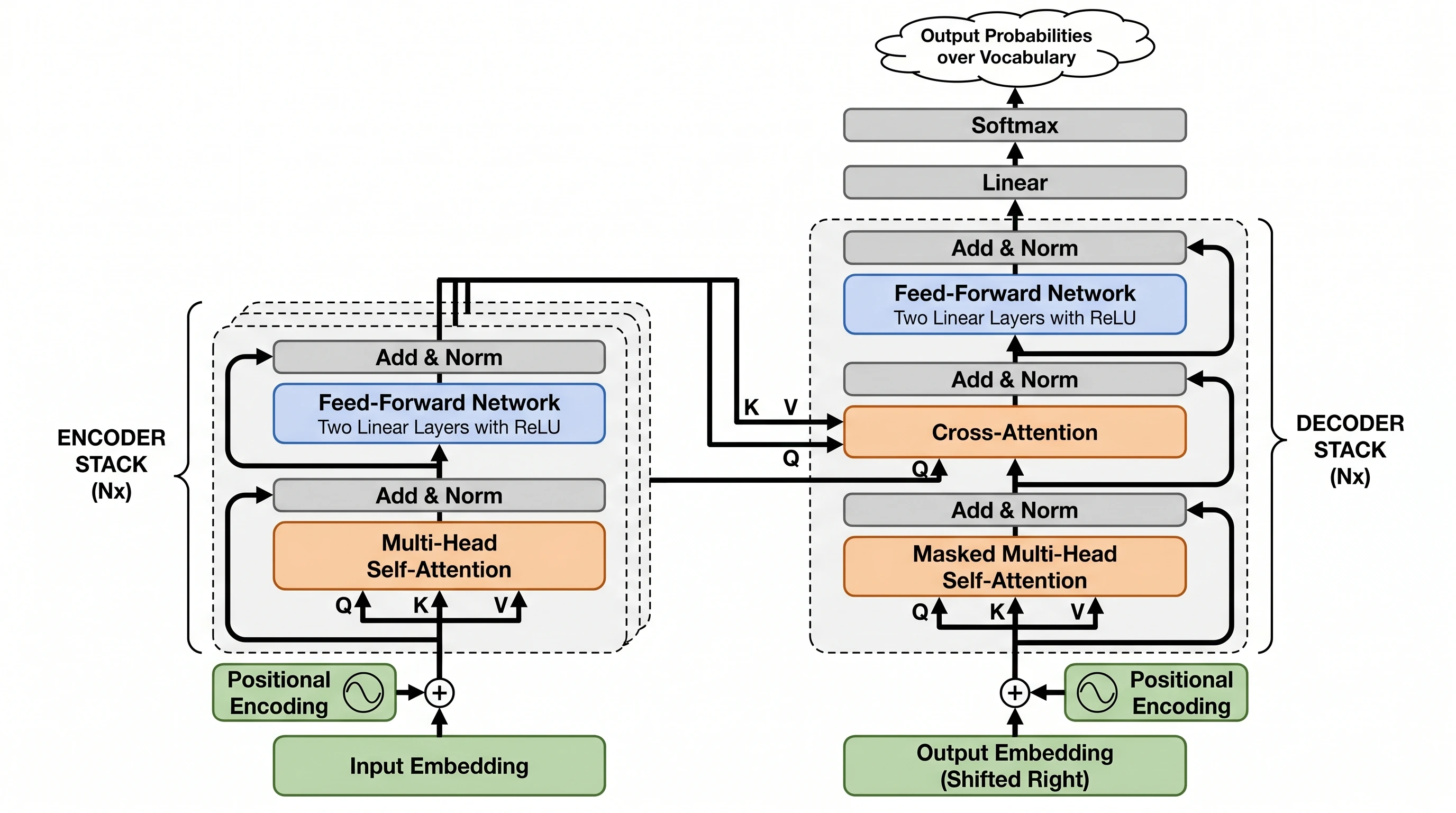
Nano Banana Pro — mêmes composants, mais l'encodeur/décodeur sont rendus comme des blocs en couches visuellement empilés (l'empilement Nx), les flèches K/V/Q de cross-attention tracent explicitement de l'encodeur au décodeur, et l'encodage de position obtient même une petite icône en forme d'onde. L'intuition structurelle gagne ici. Score 18/20.
2. La fidélité aux prompts longs est un écart de 13 points, pas un petit écart
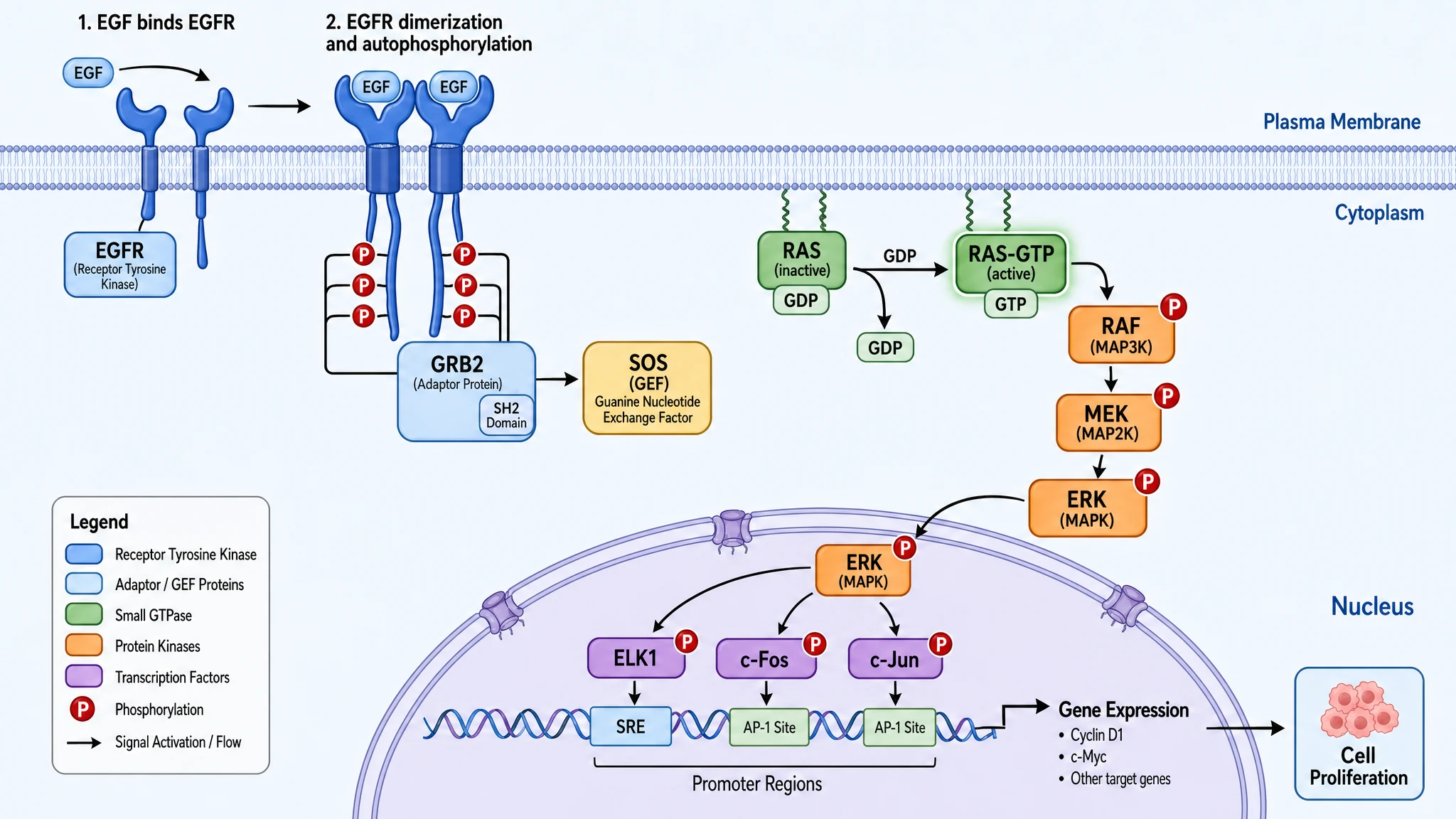
GPT Image 2 — cascade de signalisation complète avec échange GDP→GTP explicite, étiquetage en deux étapes (1 : liaison EGF, 2 : dimérisation + autophosphorylation), les trois facteurs de transcription (ELK1 / c-Fos / c-Jun), régions promotrices (SRE / AP-1 Site), gènes cibles spécifiques (Cyclin D1, c-Myc), et une légende de couleur à six catégories. 100 % de fidélité au prompt.
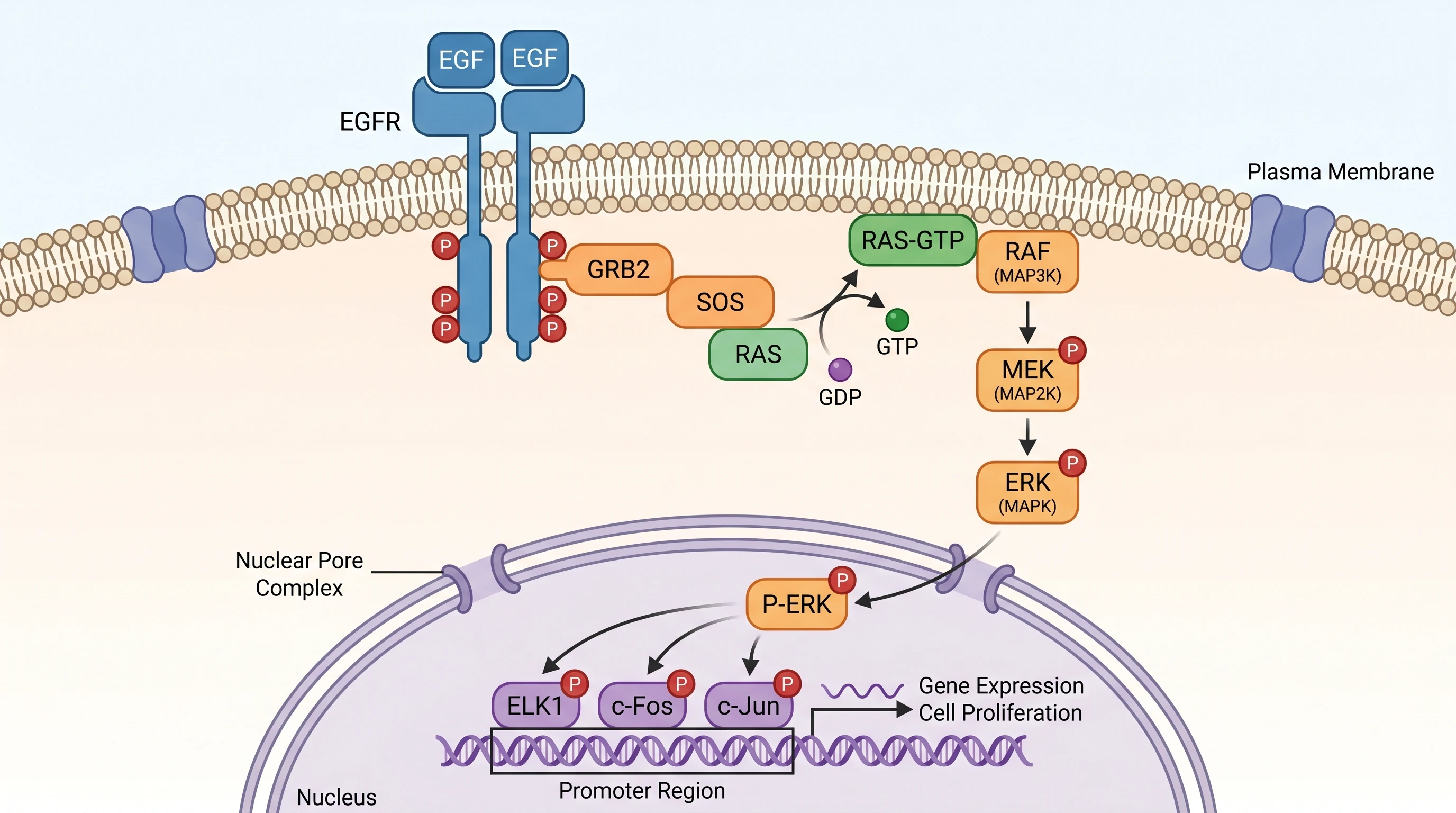
Nano Banana Pro — même exactitude scientifique sur la cascade, avec un beau détail anatomique (Complexe de Pore Nucléaire montré explicitement), mais sans la légende de couleur, la classification du promoteur SRE/AP-1 Site, les gènes cibles spécifiques (Cyclin D1, c-Myc), et l'annotation du domaine SH2. 80 % de fidélité au prompt. Même biologie — moins de notes de bas de page.
3. Le modèle qui « suit mieux les instructions » n'est pas nécessairement le modèle qui « a meilleure apparence »
Le score de fidélité plus élevé de GPT Image 2 ne se traduit pas par des figures universellement plus belles. Scores esthétiques moyens : 4,75 (GPT) vs 4,83 (NBP). Nano Banana Pro a légèrement devancé GPT Image 2 en qualité visuelle malgré le placement de moins d'éléments demandés — parce que ce qu'il a placé a été rendu avec plus de soin.
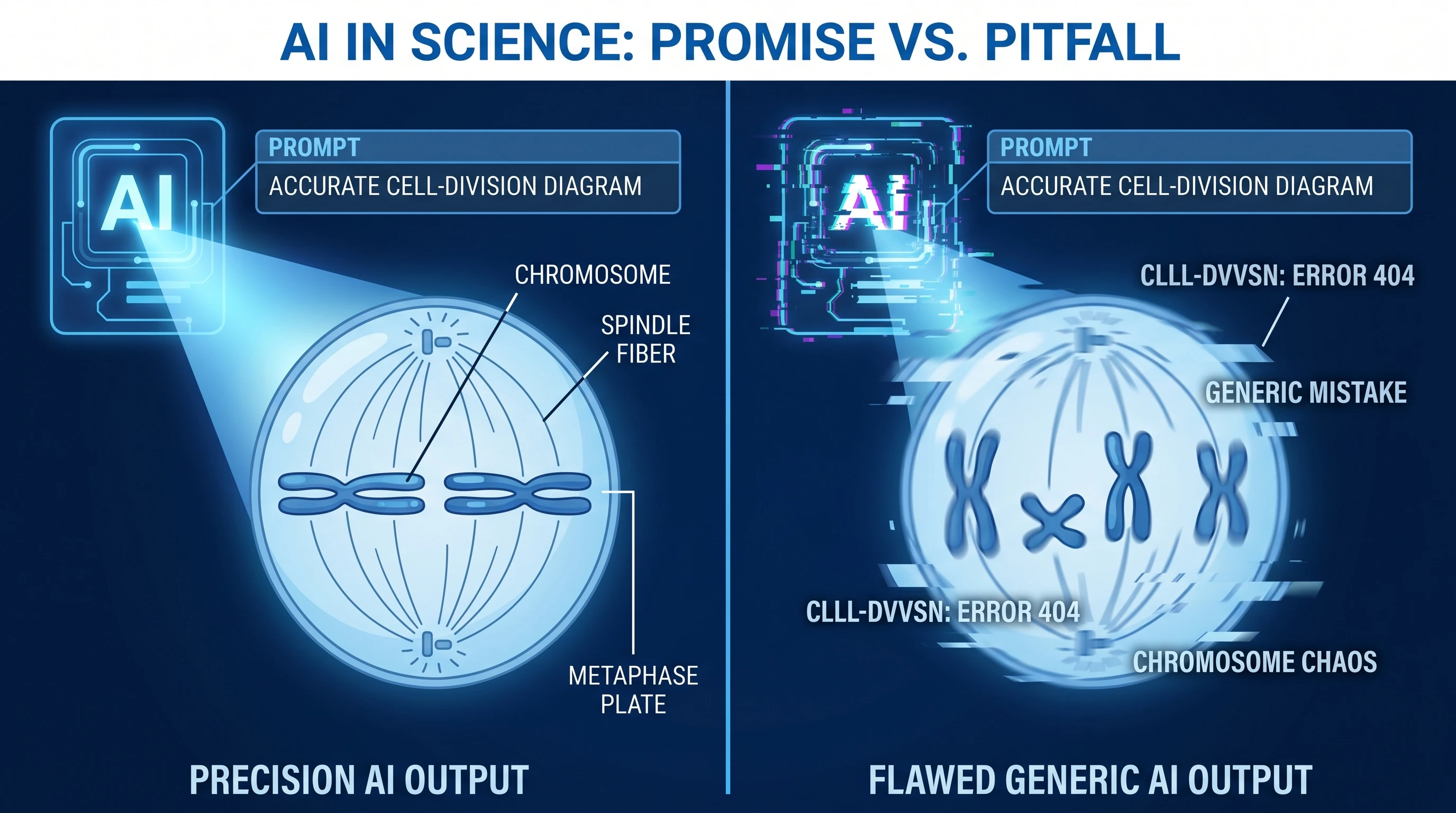
4. Nano Banana Pro peut halluciner entièrement le mauvais concept
5. Les deux modèles peuvent produire des figures de qualité couverture Nature
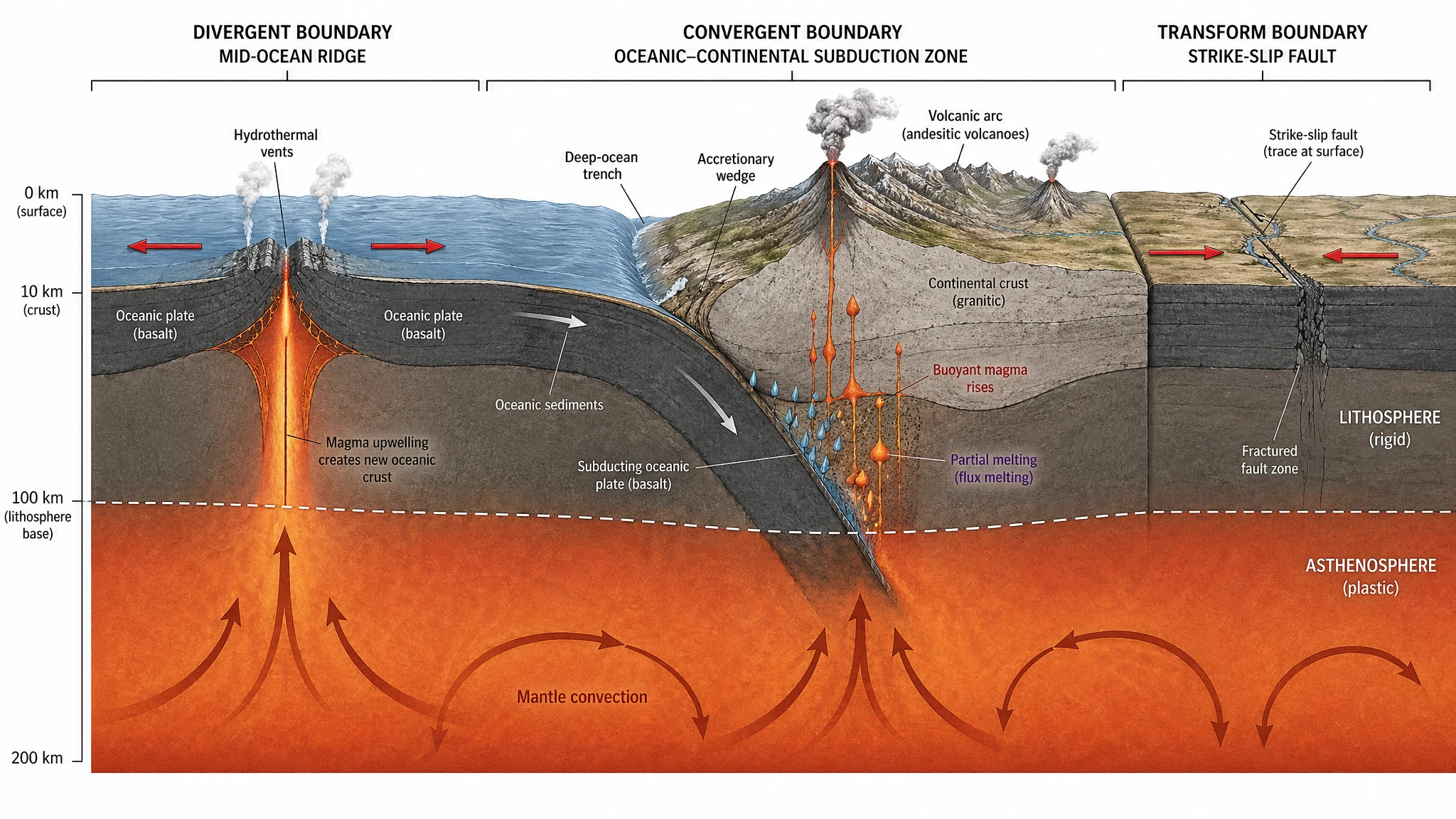
Notre test de tectonique des plaques a obtenu 19/20 pour les deux modèles. Les diagrammes de coupe géologique qui en sont sortis — trois types de frontières côte à côte, distinction lithosphère/asthénosphère, cellules de convection mantellique, échelle verticale de profondeur — ressemblent à des figures de National Geographic ou des publications de l'USGS. Le choix entre les deux pour les figures éditoriales haut de gamme est davantage une question de préférence esthétique qu'un écart de capacité. Le test du disque d'accrétion de trou noir a fait le même point — les deux modèles ont atteint la qualité d'image de couverture sur un prompt astrophysique difficile.
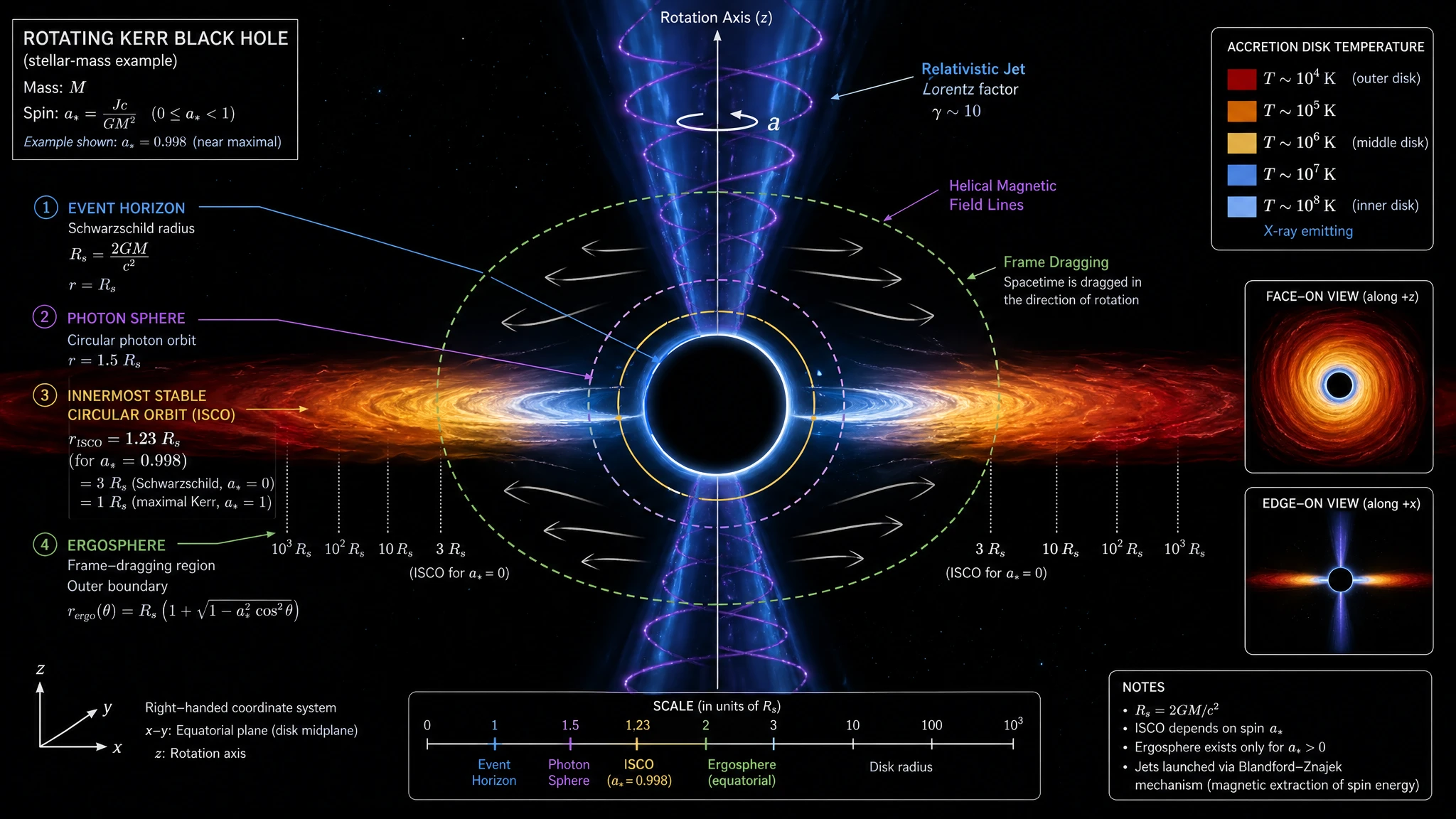
GPT Image 2 — niveau revue d'astrophysique : titré « ROTATING KERR BLACK HOLE », quatre frontières étiquetées (Event Horizon, Photon Sphere 1.5 Rs, ISCO, Ergosphere), gradient de température du disque d'accrétion (10⁴ K → 10⁸ K) avec une légende latérale, lignes de champ magnétique hélicoïdales traversant le jet, flèches d'entraînement de cadre, axes de coordonnées droitiers, encart multi-vues (face + tranche), boîte de notes avec référence au mécanisme Blandford-Znajek.
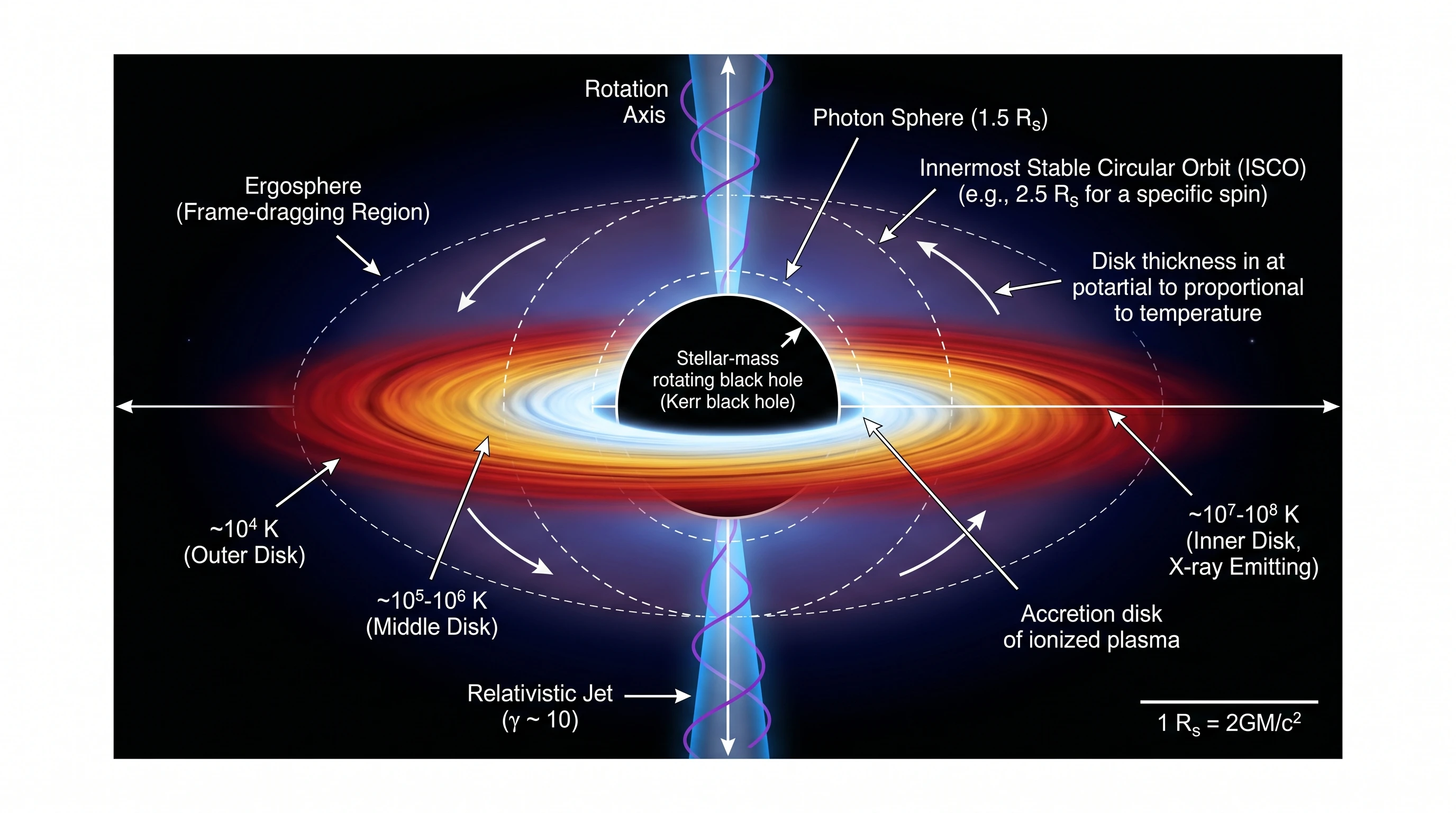
Nano Banana Pro — même exactitude scientifique, même gradient de température encodé par couleur, épaisseur du disque d'accrétion explicitement notée comme proportionnelle à la température. Légèrement moins d'annotations (pas de système de coordonnées, pas d'encart multi-vues, pas d'étiquettes de champ magnétique), mais visuellement assez frappant pour atterrir sur une couverture de magazine. Notez l'espace négatif délibéré entourant le sujet — Nano Banana Pro tend à laisser à la figure de l'espace pour respirer dans les prompts d'astrophysique, en contraste avec le cadrage dense en information de GPT Image 2 ci-dessus. C'est en soi une différence de philosophie de composition qui mérite d'être vue sur le même écran.
Quand générer à partir des deux
Il existe trois situations où exécuter les deux modèles sur le même prompt est le bon mouvement :
- Figures à enjeux élevés. Figure 1 d'article, image de couverture de proposition de subvention, diapositive de défense de thèse. Le coût de générer deux fois est de deux tours de crédits ; le coût de choisir le mauvais modèle est de jours de révisions ou d'une subvention ratée.
- Concepts non familiers ou abstraits. Tout en topologie, mathématiques avancées, physique fondamentale ou un domaine pour lequel vous n'êtes pas sûr que l'un ou l'autre modèle ait vu beaucoup de données d'entraînement. La vérification visuelle compte.
- Test A/B de style. Lorsque vous ne savez vraiment pas si votre public préfère le style dense de GPT Image 2 ou le style éditorial de Nano Banana Pro. Générez les deux, montrez-les à un collègue, choisissez par réaction.
Pour les 80 % de figures de routine — spécification scientifique claire, sujet courant, faible ambiguïté — choisissez un modèle par défaut basé sur le cadre ci-dessus et ne gaspillez pas de crédits. Pour les 20 % où le coût de l'erreur est élevé, exécutez les deux.
Pourquoi nous faisons confiance à ce verdict
Ce guide est ancré dans un benchmark que nous avons exécuté spécifiquement pour lui : 12 prompts scientifiques couvrant 10 disciplines, générés via Kie.ai (le même fournisseur d'API que SciFig utilise en production), chacun noté sur six dimensions avec des grilles explicites et un raisonnement enregistré. Les deux modèles ont été testés le même jour avec des paramètres identiques : ratio d'aspect 16:9, résolution 2K.
/inspiration?model=gpt-image-2 et /inspiration?model=nano-banana-pro. La matrice de notation complète est dans le post de benchmark compagnon. Si vous relancez un prompt et obtenez un résultat différent, c'est une information utile — dites-le-nous, s'il vous plaît. La transparence est intentionnelle : les revendications marketing d'OpenAI et de Google sont invérifiables ; les tests reproductibles côte à côte sont le seul moyen honnête de comparer les modèles phares en 2026.Conseil